# Redis源码分析
# Redis单线程为啥快
- 内存操作
- 专门设计的数据结构简单
- 避免上下文切换与竟争条件,无多线程和切换带来的cpu消耗
- 不用考虑锁的问题及死锁带来的性能消耗
- IO多路复用,非阻塞IO
- 构建自己VM机制
# Redis数据格式
- 基础数据格式:String、List、Set、ZSet、Hash
| 结构类型 | 值 | |
|---|---|---|
| String字符串 | 字符串、整数、符点数 | 对整个字符串或一部分进行操作; 对整数或符点数自增自减操作; |
| List列表 | 链表上每个节点都包含一个字符串 | 两端进行push和pop;读取单个或多个元素;根据值查找与删除; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法存在检查、获取、删除;计算交集、并集、差集等; |
| Hash散列 | 键值对的无序散列列表 | 添加、获取、删除单个元素 |
| ZSet有序集合 | 与散列一样,存储健值对 | 字符串成员与浮点数分数之间有序映射;元素排列顺序由分数大小决定;添加、获取、删除单个元素及根据分会范围或成员获取元素; |
- 特殊数据格式:HyperLogLogs基数统计 Bitmaps位图 Geospatial地理位置
# Redis的对象机制
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码方式
unsigned encoding:4;
// LRU - 24位, 记录最末一次访问时间(相对于lru_clock);
// LFU(最少使用的数据:8位频率,16位访问时间)
unsigned lru:LRU_BITS; // LRU_BITS: 24
// 引用计数
int refcount;
// 指向底层数据结构实例
void *ptr;
} robj;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
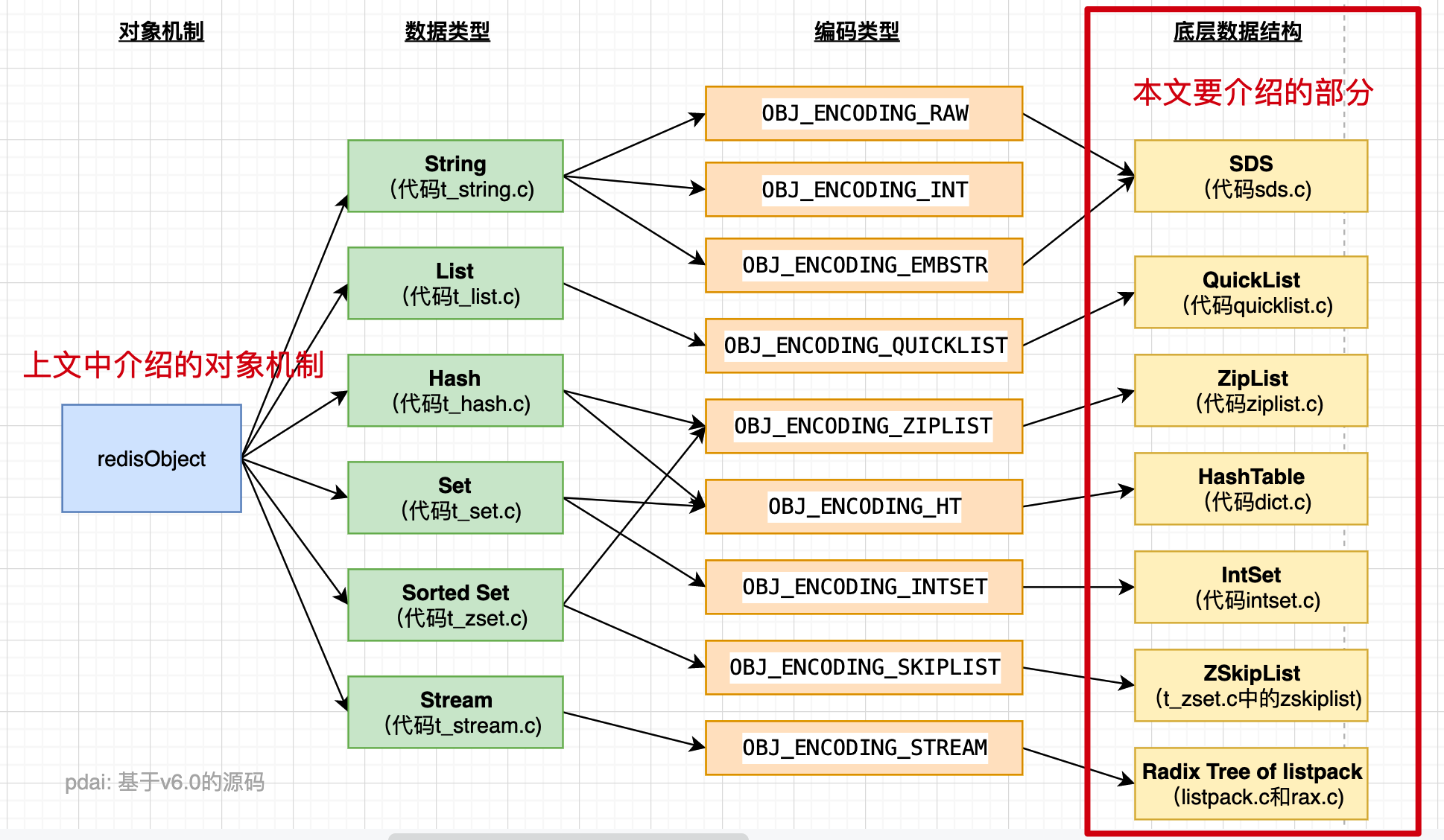
# 数据类型、编码类型、底层数据结构
数据类型
- String: OBJ_ENCODING_RAW、OBJ_ENCODING_INT、OBJ_ENCODING_EMBSTR
- List: OBJ_ENCODING_QUICKLIST
- Hash: OBJ_ENCODING_ZIPLIST、OBJ_ENCODING_HT
- Set: OBJ_ENCODING_HT、OBJ_ENCODING_INTSET
- SortedSet: OBJ_ENCODING_ZIPLIST、OBJ_ENCODING_SKIPLIST
- Stream: OBJ_ENCODING_STREAM
编码类型
- OBJ_ENCODING_RAW
- OBJ_ENCODING_INT
- OBJ_ENCODING_EMBSTR
- OBJ_ENCODING_QUICKLIST
- OBJ_ENCODING_ZIPLIST
- OBJ_ENCODING_HT
- OBJ_ENCODING_INTSET
- OBJ_ENCODING_SKIPLIST
- OBJ_ENCODING_STREAM
底层数据结构
- SDK:OBJ_ENCODING_RAW、OBJ_ENCODING_EMBSTR
- QuickList:OBJ_ENCODING_QUICKLIST
- ZipList:OBJ_ENCODING_ZIPLIST
- HashTable:OBJ_ENCODING_HT
- IntSet:OBJ_ENCODING_INTSET
- ZSkipList:OBJ_ENCODING_SKIPLIST
- Redix Tree Listpack:OBJ_ENCODING_STREAM
# SDS设计
- 字符串长度常数复杂度
- 兼容部分C字符串函数
- 杜绝缓冲区溢出
- 减少内存重分配
- 空间预分配
- 惰性释放空间
- 二进制安全
# 队列实现
- PUB/SUB:消息未执久化
- List LPush RPop或SortSet:不支持多播,消费分组等
- Stream:即时通信、大数据分析、异地数据备份等场景、支持水平扩展消费者
- 消息ID:毫秒时间戳-序号
- 维护一个latest_generated_id,记录最后一个消息的ID,时间回拨时,采用时间戳不变,序号递增的方案生成新的消息ID
- Pending列表:记录读取未处理完毕的消息(消息ID、所属消费者、已读取的时长、被读取的次数)
- 死信消息:XDEL删除
# Redis子进程如何复制内存数据
操作系统提供的写时复制机制,避免一次性拷贝大量内存数据给子进程造成阻塞。子进程拷贝父进程的页表,即虚实映射关系(虚拟内在和物理内在的映射索引表),而不会拷贝物理内存。拷贝完成前会阻塞主线程,并占用大量的cpu资源。拷贝完成后,父子进程使用相同的内存地址空间。
主进程有数据写入时,拷贝物理内存中的数据,而子进程仍旧使用原来的页。
子进程重写日志完成后,主进程追加aof重写缓冲区
# Redis过期数据删除策略
单机版本:
- 惰性删除
- 定期删除
主从复制场景:从节点不主动删除数据,而由主节点控制从节点中过期数据的删除。Redis3.2中,从节点读取数据时,增加了数据是否过期的判断;
# 内存淘汰的算法
- 不淘汰:noeviction
- 设置过期时间的数据进行淘汰
- 随机 volatile-random
- Til :volatile-ttl
- Lru:volatile-lru
- Lfu: volatile-lfu
- 全部数据淘汰
- 随机: alleys-random
- Lru: allkeys-lru
- Lfu: allkeys-lfu
LRU: 最近最少使用原则
Redis在redisObject中记录每个数据最后一次访问的时间戳,在淘汰数据时,一次性随机选择N个数据,按下来比较它们的LRU字段,把LRU字段值最小的数据从缓存中淘汰出去。Redis不用维护和操作链表,从而提高了性能
LFU:在LRU的策略基础上,添加一个访问次数的计数器。会把访问次数最低的数据淘汰出缓存。Redis根据lru字段后8位选择访问次数最少的数据,当访问次数相同时,根据前16位选择访问时间最久的数据进行淘汰
# Redis优化
- 缩小键值对象的长度
- 共享对象池,【0~9999】的整数对象池
- 字符串优化
- 编码优化
- 控制key的数量
# Redis主从复制
- 数据冗余
- 故障隔离
- 负载均衡
- 高可用
全量(同步)复制:第一次同步
增量(同步)复制:主从库网络断开期间主库收到的命令,同步给从库
# Redis全量复制
建立连接,协商同步 Psync(主库runID=-1表示第一次复制, offset复制进度)
FullReSync(主库runId,主库目前的复制进度offset)
主库同步数据给从库 主库执行bgsave,生成RDB文件,并将文件发给从库,从库收到后,清空当前数据库,加载RDB文件。 主库在内在中记录replication buffer,记录RDB文件生成后收到的所有写操作
主库把二阶段新收到写命令,发送给从库
# Redis增量复制
2.8之后开始,网络闪断,无需要全量复制
- replication buffer:从库断开后,如何找到主从差异而设计的环形缓冲区。如果断开时间太久,缓冲区被写覆盖,则需要进行全量复制
- repl_backlog_buffer:主从增量同步过程中,从库作为client,主库会分配一个buffer,专门用来传播用户的写命令到从库,从而保证数据的一致
每个从库会记录自己的slave_repl_offset,在和主库重连恢复时,从库通过psync命令把自己的slave_repl_offset发给主库,主库根据从库的复制进度,决定这个从库是增量,还是全量
# 无磁盘复制
Repl-diskless-sync
Repl-diskless-sync-delay
# 从库的从库
# 哨兵
- 监控:检查主节点从节点是否运行正常
- 自动故障迁移
- 配置提供者
- 通知:故障转移结果发送客户端
# 哨兵判断主库下线的策略
- 主观下线:哨兵通过监控探测主节点
- 客观下线:哨兵集群共同决定主节点是否下线
# Redis网络事件处理
IO多路复用,同时监听多个套接字,并为套接字关联不同的事件处理函数
IO多路复用程序将所有产生的套接字放到同一个队列(aeEventLoop的fired就绪事件表),然后事件处理器以有序,同步,单个套接字的方式处理
# Redis Cluster哈希槽
2^14=16384个槽,CRC16校验后16383取槽