# 16 控制器模式(设计方法)
统一地实现对各种不同对象或者资源进行编排操作
# 实际状态来自于kubernetes集群本身
- 心跳汇报的容器和节点状态
- 监控系统中保存的应用监控数据
- 控制器主动收集的它自己感兴趣的信息
# 期望状态一般来自于用户提交的YAML文件
Deployment:负责定义被管理对象的期望状态
PodTemplate:Pod模板
################################
# app_name = nginx-deployment
################################
# 控制器定义:期望状态
apiVersion: apps/v1
kind: Deployment
metadata:
name: {app_name}
label:
app: {app_name}
namespace: {NS}
spec:
replicas: 2
selector:
matchLabels:
app: {app_name}
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
# 被控制对象:模板
template:
metadata:
labels:
app: {app_name}
spec:
containers:
- name: java
image: {image_uri}
command:
- "bash"
- "-c"
- "java xxxx -jar xxxx"
ports:
- containerPort: 8080
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 17 作业副本与水平扩展
# 概念
- Deployment:pod水平扩展/收缩
- ReplicaSet:Deployment的一个子集,由副本数目的定义和一个Pod模板组成;Deployment实际操纵的对象;
- 滚动更新
- Pod-template-hash:Dployment提交后,Deployment Controller创建的ReplicaSet的名字后添加的随机字符串
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# DeployMent
升级方案:
- Recreate;删除已有的pod,重新创建新的
- RollingUpdate;滚动升级,逐步替换。支持设置最大不可用数量,最小升级间隔等
重要参数:
- maxSurge:1表示滚动升级时先启动1个pod
- maxUnavailable:1表示滚动升级时允许的最大不可用pod的个数
- teerminationGracePeriodSeconds:默认30s给应用发送SIGTERM信号
- Pre-stop lifecycle hook配置声明,在发送SIGTERM之前执行
- livenessProbe:存活判定
- readinessProbe:启动成功
- reeadinessProbe.initialDelaySeconds
# 滚动更新
# 四个状态:
kubectl create -f nginx-deployment.yaml --record
kubectl rollout status deployment/nginx-deployment
kubectl get rs
# 查看滚动更新的流程
kubectl describe deployment nginx-deployment
2
3
4
5
- Desired:期望的Pod副本个数spec.replicas
- Current:当前处理Running的Pod个数
- Up-to-date:处理最新版本的pod个数
- Available:当前可用
- Running状态
- 最新版本
- Ready状态(健康检查正确)
# Deployment、ReplicaSet 和 Pod 的关系图
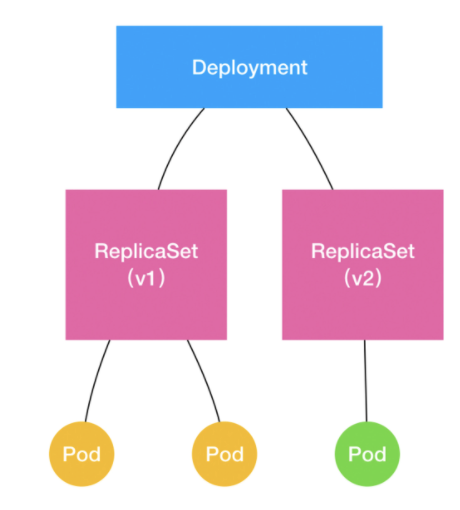
kubectl set image deployment/nginx-deployment nginx=nginx:1.91
kubectl rollout undo deployment/nginx-deployment
kubectl rollout history deployment/nginx-deployment --revision=2
kubectl rollout pause deployment/nginx-deployment
2
3
4
# 如何控制ReplicaSet的数量
Deployment 对象有一个字段,叫作 spec.revisionHistoryLimit
# 18 StatefullSet 拓扑状态
# 概念
- 有状态应用:Stateful Application 实例之间有不对等关系,以及实例对外部数据有依赖关系的应用
- 拓扑状态:应用实例之间不对等,必须按某些顺序启动,并且新的pod必须与旧的网络标识一样
- 存储状态:多个实例分别绑定了不同的存储数据
- Service:用来将一组pod暴露给外界访问的一种机制
- PVC:一种特殊的volume,只有和PV绑定后才能知道具体的类型
# StatefullSet
- 设计:拓扑状态、存储状态
- 记录,恢复
# Service如何被访问
- 虚拟IP方式
- DNS方式
唯一的“可解析身份
<pod-name>.<svc-name>.<namespace>.svc.cluster.local- Normal Service:解析到服务的虚拟IP地址
- Headless Service:解析到某一个Pod的IP地址
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
selector:
app: nginx
clusterIp: None
ports:
- port: 80
name: web
# 值是:None,即:这个 Service,没有一个 VIP 作为“头”。这也就是 Headless 的含义。所以,这个 Service 被创建后并不会被分配一个 VIP,而是会以 DNS 记录的方式暴露出它所代理的 Pod
2
3
4
5
6
7
8
9
10
11
12
13
14
# 拓扑状态维护
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
# nginx-deployment 的唯一区别,就是多了一个 serviceName=nginx
# 就是告诉 StatefulSet 控制器,在执行控制循环(Control Loop)的时候,请使用 nginx 这个 Headless Service 名字,来保证 Pod 的“可解析身份”
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
$ kubectl create -f svc.yaml
$ kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 10s
$ kubectl create -f statefulset.yaml
$ kubectl get statefulset web
NAME DESIRED CURRENT AGE
web 2 1 19s
# Watch 功能
$ kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
2
3
4
5
6
7
8
9
10
11
12
13
14
15
StatefulSet给所有管理的Pod进行了编号
<statefulset name>-<ordinal index>编号从0开始,不重复;创建也是按编号进行
设置:livenessProbe readinessProbe的重要性
StatefulSet 就保证了 Pod 网络标识的稳定性
StatefulSet 这个控制器的主要作用之一,就是使用 Pod 模板创建 Pod 的时候,对它们进行编号,并且按照编号顺序逐一完成创建工作。而当 StatefulSet 的“控制循环”发现 Pod 的“实际状态”与“期望状态”不一致,需要新建或者删除 Pod 进行“调谐”的时候,它会严格按照这些 Pod 编号的顺序,逐一完成这些操作。
# 19 StatefulSet 存储状态
# 挂载方式
- ReadWriteOnce:被一个节点以读写方式挂载
- ReadOnlyMany:卷可被多个节点以只读方式挂载
- ReadWriteMany:多个节点读写方式挂载
- ReadWriteOncePod:单个Pod挂载
Persistent Volume Claim 执久卷声明
# 1. 定义pvc声明想要的volume属性
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-claim
spec:
accessModes:
# 挂载方式是可读写,并且只能被挂载在一个节点上而非被多个节点共享
- ReadWriteOnce
resources:
request:
# 大小至少是 1 GiB
storage: 1Gi
2
3
4
5
6
7
8
9
10
11
12
# 2. 在应用的pod中,声明使用pvc
apiVersion: v1
kind: Pod
metadata:
name: pv-pod
spec:
containers:
- name: pv-container
image: nginx
ports:
- containerPort: 8080
name: http-server
volumeMounts:
- mountPath: /usr/share/nginx/html
name: pv-storage
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: pv-claim
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3. 运维同学的pv(Persistent Volume)对象
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-volume
labels:
type: local
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
rbd:
monitors:
# 使用kubectl get pods -n rook-ceph 查看 rook-ceph-mon- 开关的pod ip则可得下面的列表
- '10.16.154.78:6789'
- '10.16.154.82:6789'
- '10.16.154.83:6789'
pool: kube
image: foo
fsType: ext4
readOnly: true
user: admin
keyring: /etc/ceph/keyring
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
如何关联到特定的pv:对pv打label的方式:
pv:
...
metadata:
labels:
pv: nfs-pv2
...
2
3
4
5
Pvc:
...
spec:
...
selector:
matchLabels:
pv: nfs-pv2
2
3
4
5
6
7
- 职责分离:避免向开发者暴露过多存储细节带来的隐患,出事故时更容易定位问题与明确责任
- 降低用户声明和使用的门槛
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
#
serviceName: nginx
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
查看
$ kubectl create -f statefulset.yaml
$ kubectl get pvc -l app=nginx
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
www-web-0 Bound pvc-15c268c7-b507-11e6-932f-42010a800002 1Gi RWO 48s
www-web-1 Bound pvc-15c79307-b507-11e6-932f-42010a800002 1Gi RWO 48s
2
3
4
5
<pvc名称>-<StatefulSet名字>-<编号>命名
# 总结
- StatefulSet控制器直接管理的是Pod
- Pod实例有细微的差别
- 通过Headless Service,为这些有编号的Pod,在DNS中生成带有同样编号的DNS记录
- 为每一个Pod分配并创建一个同样编号的PVC
StatefulSet是一种特殊的Deployment,它为每个pod编号,而且编号会体现在Pod的名称和hostname等标识信息上,不仅代表了pod的创建顺序,也是pod重要的网络标识;有了这个编号后,StatefulSet 就使用 Kubernetes 里的两个标准功能:Headless Service 和 PV/PVC,实现了对 Pod 的拓扑状态和存储状态的维护
# 20 有状态应用实践
# 三座大山
- master和slave需要有不同的配置文件
- master和slave需要能够传输备份的信息文件
- slave第一次启动之前,需要执行一些初始化sql
# 解决
# 1. configmap配置不同的配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
[mysqld]
log-bin
slave.cnf: |
[mysqld]
super-read-only
2
3
4
5
6
7
8
9
10
11
12
13
- master开启log-bin,即:使用二进制日志文件进行主从复制;
- slave开启了super-read-only,代表从节点会拒绝主节点同步操作之外所有写操作
# 2. 创建2个service来供StatefulSet及用户使用
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None # Headless Service,是通过为 Pod 分配 DNS 记录来固定它的拓扑状态
selector:
app: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 3. 备份文件的传输(先框架,再细节)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql # 管理的 Pod 必须携带 app=mysql 标签
serviceName: mysql # 要使用的 Headless Service 的名字是:mysql
replicas: 3
template:
metadata:
label:
app: mysql
spec:
initContainers:
- name: init-mysql # ...
- name: clone-mysql # ...
containers:
- name: mysql # ...
- name: xtrabackup # ...
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
store: 10Gi
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 4. 第一步:从 ConfigMap 中,获取 MySQL 的 Pod 对应的配置文件
从pod的hostname中读取pod的编号,以些做为mysql节点的serverid
通过编号判断是master还是slave(序号从0开始)
... - name: init-mysql # ... # 取server-id image: mysql:5.7 command: - bash - "-c" - | set -ex # 从Pod的序号,生成server-id [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} echo [mysqld] > /mnt/conf.d/server-id.cnf # 由于server-id=0有特殊含义,我们给ID加一个100来避开它 echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf # 如果Pod序号是0,说明它是Master节点,从ConfigMap里把Master的配置文件拷贝到/mnt/conf.d/目录; # 否则,拷贝Slave的配置文件 if [[ $ordinal -eq 0 ]]; then cp /mnt/config-map/master.cnf /mnt/conf.d/ else cp /mnt/config-map/slave.cnf /mnt/conf.d/ fi volumeMounts: - name: conf mountPath: /mnt/conf.d - name: conf-map mountPath: /mnt/config-map ...1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 5. 在slave pod启动前,从Master或者其它slave pod中拷贝数据到自己目录
...
# template.spec.initContainers
- name: clone-mysql
image: gcr.io/google-samples/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# 拷贝操作只需要在第一次启动时进行,所以数据已经存在,跳过
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Master节点,序号为0,不需要做这个操作
[[ `hostname` =~ -([0-9]+)$ ]] && exit 1
ordinal=${BASH_REMATCH[1]}
# 使用ncat命令,远程从前一个节点拷贝数据到本地
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 执行--prepare,这样拷贝来的数据就可用作恢复了
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 6. 启动服务的初始化操作
# 21 容器化守护进程
# 字典
kubectl path以“补丁”的方式(JSON 格式的)修改一个 API 对象的指定字段
修改 StatefulSet 的 Pod 模板,就会自动触发“滚动更新”:
kubectl path statefulset mysql --type='json' -p '[{"op": "replace", "path":"", "value":"mysql:5.7.23"}]'
spec.updateStrategy.rollingUpdate.partition滚动升级指定一部分不更新到最新版本,只有序号大于等于2的才会被更新到最新的状态
kubectl path statefulset mysql -p '{"spec":{"updateStrategy":{"type":"RollingUpdate", "rollingUpdate":{"partition":2}}}}'
# DaemonSet:
# 特点
- 运行在指定的每一个节点上
- 每个节点上只有一个实例
- 有新的节点加入集群,会被自动创建出来,删除后也会相应的被回收掉
# 适用
- 网络插件的agent,用来处理节点上的容器网络
- 存储插件的agent,用来处理节点上挂载远程存储目录,操作容器的volume目录
- 监控组件及日志组件,负责这个节点的监控信息和日志搜集
# 示例
apiVersoin: apps/v1
kind: DeamonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-loging
spec:
# 选择所有携带name=的Pod
selector:
matchLabels:
name: fluentd-elasticsearch
template:
matadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontaineres
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
host: /var/log
- name: varlibdockercontaineres
hostPath:
# Docker默认的日志目录,`/var/lib/docker/containers/{{.容器ID}}/{{.容器ID}}-json.log
path: /var/lib/docker/containers
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 保证Node上有且只有一个Pod
# 情况
- 没有,需要创建 => 在指定的Node上创建Pod
- 有,数量大于1,需要删除 => 直接调API
- 有,数量等于1,不需要处理
# 解决
如何在指定的Node创建新Pod
nodeSelector: name: <Node名字>1
2apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity: nodeAffinity: # 节点亲合力 # 必须在每次调度时予以考虑 requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: # 只允许运行在下面条件的Node上 - key: metadata.name operator: In values: - node-geektime1
2
3
4
5
6
7
8
9
10
11
12
13
14
15标记
unschedulable的节点,容忍度,污点apiVersion: v1 kind: Pod metadata: name: with-toleration spec: tolerations: - key: node.kubernets.io/unschedulable operator: Exists effect: NoSchedule - key: node.kubernets.io/network-unavailable operator: Exists effect: NoSchedule1
2
3
4
5
6
7
8
9
10
11
12示例
apiVersion: app/v1 kind: DaemonSet metadata: name: xxx namespace: kube-system labels: k8s-app: fluentd-logging spec: template: spec: # k8s不允许在master上部署Pod tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule1
2
3
4
5
6
7
8
9
10
11
12
13
14# 22 离线任务Job CronJob
# controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495 # job-name=pi apiVersion: batch/v1 kind: Job metadata: name: pi spec: # label的selector会自动添加,格式: controller-uid=<一个随机字串> # 从而保证了Job与它管理的Pod之间的关系 template: spec: containers: - name: pi image: resouer/ubuntu-pc command: ["sh", "-c", "echo 'guoguo'"] restartPolicy: Nerver # 任务失败之前重试次数 backoffLimit: 4 # 任务最长运行时间 activeDeadlineSeconds: 100 # 最多同时运行 parallelism:2 # 最小完成数 completions: 41
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24$ kubectl describe jobs/piName: piNamespace: defaultSelector: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495Labels: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495 job-name=piAnnotations: <none>Parallelism: 1Completions: 11JobController直接控制pod,在控制循环中调谐 Reeconcile 操作,根据实际在Running状态的Pod数目,已经成功退出的pod数目,以及并发度,完成数等共同计算出在这个周期中,应该创建和删除的Pod的数目,然后调用Kubernets API来执行操作
# 使用场景
- 外部管理器+Job模板
- 拥有固定数量的并行Job
- 指定并行数,不固定完成数
CronJob
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hellp
spec:
schedule: "*/1 * * * *"
concurrencyPolicy: Allow # Forbid Replace
startingDeadlineSeconds: 200 # 过去200s内,如果miss的数据达到100个,这个job就不创建了
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo hello from the kubernates cluster
restartPolicy: OnFailure
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
CronJob 专门 管理Job对象的控制器
# 23 声明式API与Kubernates编程范式
命令式配置文件操作
# 替换原有API对象
kubectl create
kubectl replace
kubectl edit
kubectl set image
2
3
4
5
6
声明式操作
# 执行原有对象的Patch操作,一次处理多个写操作,并且有Merge的能力
kubectl apply
2
# Dynamic Admission Control(动态准入控制 Initializer)
**Admission Control:**可以选择性地编译进APIServer中,在api对象创建后立刻被调用到
Istio 效果:在用户提交的yaml文件中加入实现定义好的 Envoy 容器,以接管 Pod 进出流量 Istio 过程:
- 将这个 Envoy 容器本身的定义,以 ConfigMap 的方式保存在 Kubernetes 当中;
- 这个configmap的data部分,正好是envoy的pod对象的一部分定义
- 编写“自定义控制器”(Custom Controller)(Initializer); 将编写好的Initializer作为 Pod 部署; 它在运行时,不停获取实际状态,然后与期望状态对比,以些做为下一部的操作
- 编写 InitializerConfiguration ,来指定对什么样的资源进行 Initializer操作,并且在新Pod创建时添加 metadata.initializers.pending 标志,Initializer判断有没有初始化的重要依据;
- Initializer 通过 Kubernetes 的“控制循环”机制,遍历获取新创建的符合筛选条件(metadata.initializers.pending)的 Pod,检查期望状态(Pod里添加了Envoy容器的定义)与实际状态 ,修改该Pod的API对象,然后清除metadata.initializers.pending 标志。
Initializer 过程:
- 从APIServer中拿到ConfigMap,将其中containers与volumes字段添加进空Pod对象;
- 调用 Kubernetes API库 strategicpatch.CreateTwoWayMergePatch(pod, newPod),生成新旧Pod对象的TwoWayMergePatch ;
- 调用 Kubernetes 的 Client,以TwoWayMergePatch 为参数发起一个 PATCH 请求,用户提交的Pod里添加了ConfigMap中的Envoy容器相关字段。
示例:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ["sh", "-c", "echo hello word && sleep 3600"]
# 自动添加上Envoy容器的配置
- name: envoy
image: lyft/envoy:xxxx
command: ["/usr/local/bin/envoy"]
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
envoy如何做到的,编写了一个自动注入的Initializer
将这个ENvoy容器本身的定义放到ConfigMap中
apiVersion: v1 kind: ConfigMap metadata: name: envoy-initializer data: config: | containers: - name: envoy image: lyft/envoy:xxxxx command: ["/usr/local/bin/envoy"] args: - "--concurrency 4" - "--config-path /etc/envoy/envoy.json" - "--mode serve" ports: - containerPort: 80 protocol: TCP resources: limits: cpu: "1000m" memory: '512Mi' requests: cpu: '100m' memory: "64Mi" volumeMounts: - name: envoy-conf mountPath: /etc/envoy volumes: - name: envoy-conf configMap: name: envoy1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31Initializer,作为一个Pod在k8s中
apiVersion: v1 kind: Pod metadata: labels: app: envoy-initializer name: envoy-initializer spec: containers: - name: envoy-initializer image: envoy-initializer:0.0.1 # 一个事先写好的 Custom Controller imagePullPolicy: Always1
2
3
4
5
6
7
8
9
10
11配置什么样的资源进行操作
apiVersion: admissionregistration.k8s.io/v1alpha1 kind: InitializerConfigration metadata: name: envoy-config initializers: # 名字必须至少包含两个. - name: envoy.initializer.kubernates.io rules: - apiGroups: - "" apiVersions: - v1 resources: - pods1
2
3
4
5
6
7
8
9
10
11
12
13
14
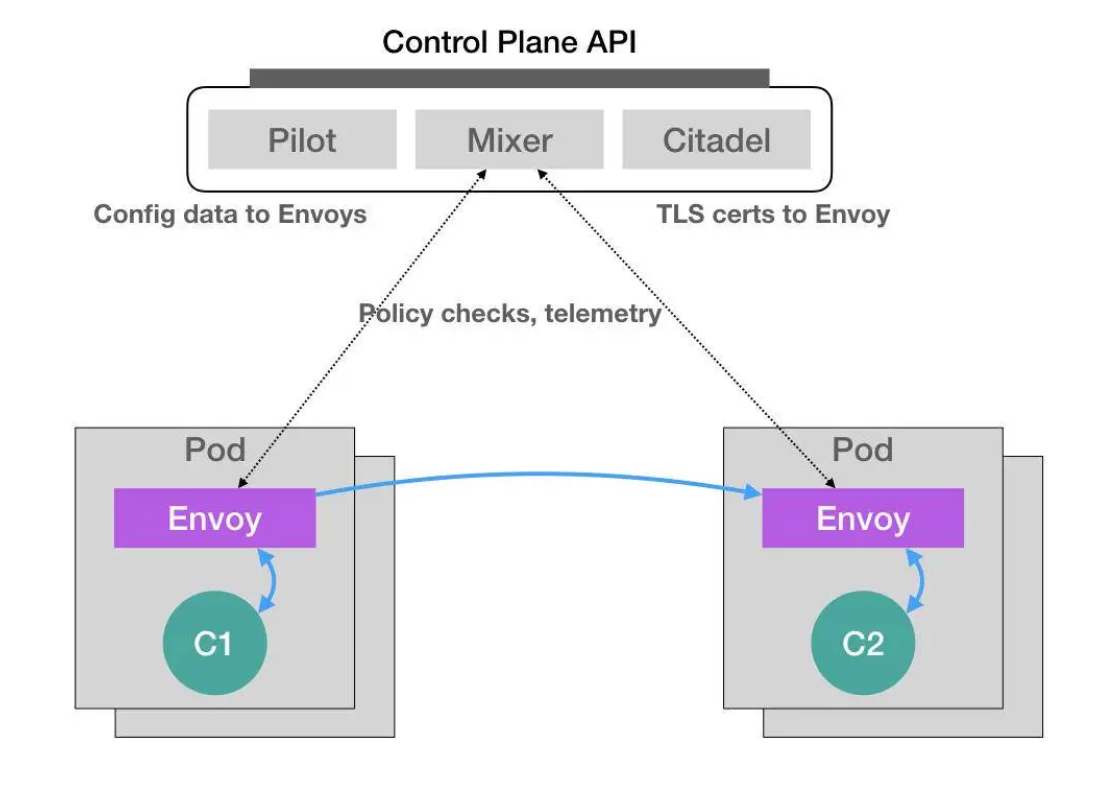
声明式的独特之处
声明式API是k8s项目编排能力“得以生存”的核心所在
- 声明式:只需要提交一个定义好的API对象来声明,我所期望的状态是什么样子的
- 允许多个API写端,以patch的方式对api对象进行修改,而不需要关心本地原始的yaml文件内容
- 完全无需要外界干预的情况下,完成对实际状态和期望状态的调谐(Reconcile)过程
“Kubernetes 编程范式”,即:如何使用控制器模式,同 Kubernetes 里 API 对象的“增、删、改、查”进行协作,进而完成用户业务逻辑的编写过程。
# 24 深入解析声明式API: 对象的奥秘
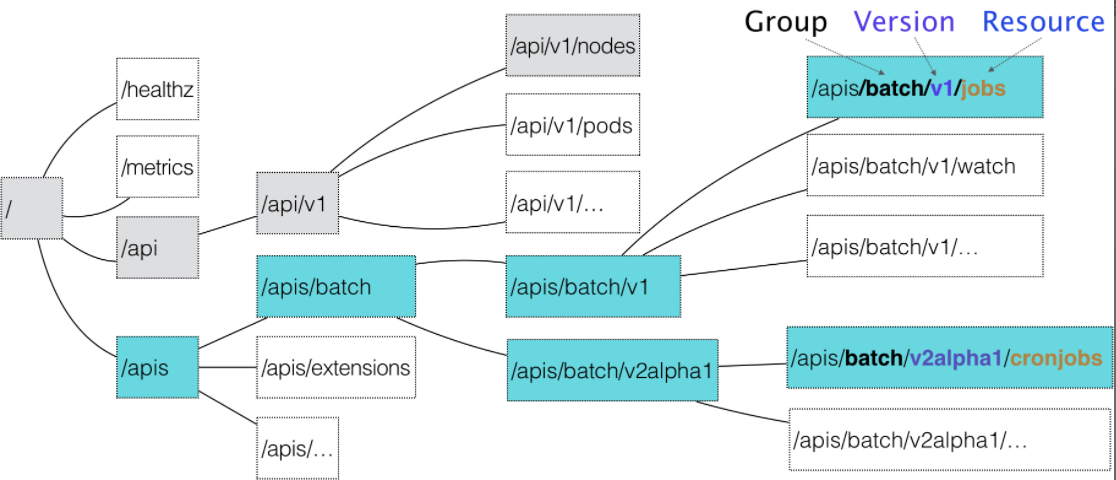
API 对象在 Etcd 里的完整资源路径,是由:Group(API 组)、Version(API 版本)和 Resource(API 资源类型)三个部分组成的
对于 Kubernetes 里的核心 API 对象,比如:Pod、Node 等,是不需要 Group 的(即:它们的 Group 是“”)。所以,对于这些 API 对象来说,Kubernetes 会直接在 /api 这个层级进行下一步的匹配过程。
如何找到对象的定义
- 匹配对象的组
- 匹配对象的版本号
- 匹配对象的资源类型
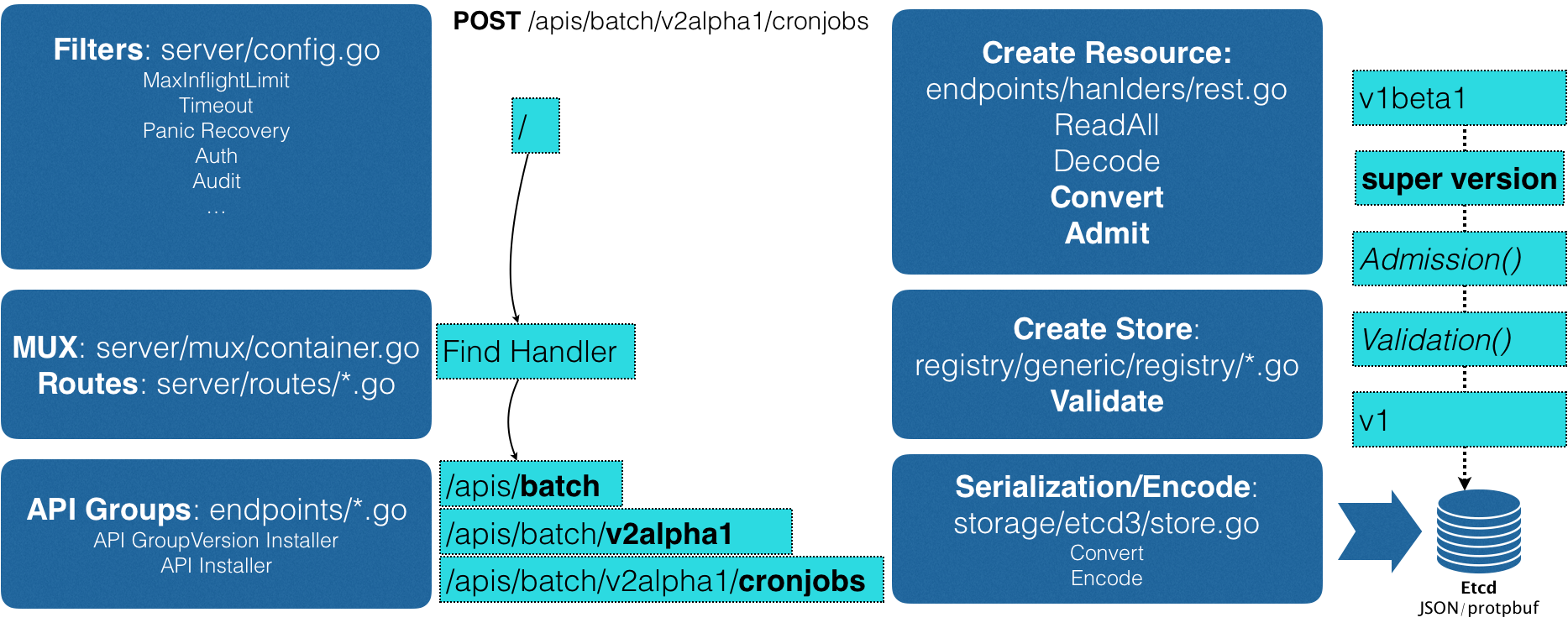
创建过程
创建CronJob的Post请求,yaml信息就提交给ApiServer
- 过滤请求,完成一些前置的工作,比如授权、超时处理、审计等
请求会进入Mux和Routes流程
- 是APIServer完成URL和handler绑定的场所。handler会按之前匹配的过程,找到CronJob类型定义
职责:根据类型定义,使用用户提交的yaml文件字段,创建一个CronJob对象
- 在这个过程中,会做转换Convert的工作:yaml->SuperVersion对象
Admission和validation操作
- Admission:准入
- Validation:负责验证对象中的字段是否合法,验证后保存在Registry的数据结构中
把验证过的API对象转换成用户最初提交的版本,进行序列化操作,并调用etcd的api保存起来
**CRD:**Custom Resource Definition,允许用户在k8s中添加一个和Pod、Node类似的,新的api资源类型
# Custem Resource
apiVersion: samplecrd.k8s.io/v1
kind: NetWork
metadata:
name: example-network
spec:
cidr: "192.168.0.0/16"
gateway: "192.168.0.1"
2
3
4
5
6
7
8
如何使可识别
# 定义一个
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: networks.samplecrd.k8s.io
spec:
# 指定了API的信息
group: samplecrd.k8s.io
version: v1
names:
kind: NetWork
plural: networks
scope: Namespaced # 声明是一个属于NS的对象,类似于Pod
2
3
4
5
6
7
8
9
10
11
12
13
在GoPATH下创建如下结构的项目
$ tree $GOPATH/src/github.com/<your-name>/k8s-controller-custom-resource
.
├── controller.go
├── crd
│ └── network.yaml
├── example
│ └── example-network.yaml
├── main.go
└── pkg
├── apis
│ └── samplecrd
│ ├── constants.go # 用来放置后来要用到的全局变量
│ └── v1
│ ├── doc.go
│ ├── register.go
│ ├── types.go
│ └── zz_generated.deepcopy.go # 自动生成
└── client # 自动生成的客户端库
├── clientset
├── informers
└── listers
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package samplecrd
const(
GroupName = "samplecrd.k8s.io"
Version = "v1"
)
2
3
4
5
6
需要定义两部分内容
- 自定义资源类型的API描述,包括:组、版本、资源类型等
- 自定义资源类型的对象描述,包括:Spec、Status等
接下来,调用生成代码工具,为自定义资源类型自动生成clientset informer lister
# 25 自定义控制器
- 编写自定义控制器的main函数:定义并初始化一个自定义控制器,然后启动它
- 根据提供的Master配置(apiserver地址和kubeconfig路径)创建一个kubeclient和network对象的client。
- 为Network对象创建一个InformerFactory工厂,并用它生成一个Network对象的Informer,传递给控制器
- 启动上面的Informer,然后执行controller.Run启动自定义控制器
Informer工作职责: 本质是一个带有本地缓存和索引机制的,可以注册EventHandler的client
- 同步本地缓存
- 触发事先注册好的ResourceEventHandler
Informer工作原理:
- 获取关心的对象:通过Informer的Refflector包维护连接,它使用ListAndWatch获取并监听对象实例的变化
- 创建、删除、更新进入Delta FIFO Queue,增量先进先出队列
- Informer读增量,然后判断类型,创建或更新本地缓存(Store)
- 每resyncPeriod指定时间,会使用最近一次list返回的结果强制更新一次本地缓存(resync)
# 26 基于角色的权限控制:RBAC
# 字典:
Role
apiVersion: rbac.authroization.k8s.io/v1 kind: Role metadata: namespace: mynamespace name: example-role rules: - apiGroups: [""] resources: ["pods"] verbs: ["get", "watch", "list"] - apiGroups: [""] resources: ["configmaps"] resourceNames:["my-config"] verbs: ["get"]1
2
3
4
5
6
7
8
9
10
11
12
13Subject
RoleBinding
apiVersoin: rbac.authroization.k8s.io/v1 kind: RoleBinding metadata: name: example-rolebinding namespace: mynamespace subjects: - kind: User # ServiceAccount Group name: example-user apiGroup: rbac.authorization.k8s.io roleRef: - kind: Role name: example-role apiGroup: rbac.authorization.k8s.io1
2
3
4
5
6
7
8
9
10
11
12
13ClusterRole
ClusterRoleBinding
ServiceAccount:内置用户 在k8s中对应的用户名字是:
system:serviceaccount:<Namespace名字>:<ServiceAccount名字>apiVersion: v1 kind: ServiceAccount metadata: namespace: mynamespace name: example-sa1
2
3
4
5Group(用户组)
对应用户组的名字
system:serviceaccount:<NameSpace名字>如果配置了外部认证服务,它会由外部认证服务提供
# 权限
verbs: ["get", "list", 'watch', "create", "update", "patch", "delete"]
# 预定义的ClusterRole
- Cluster-admin
- admin
- edit
- view
# 查看详细信息
$ kubectl get sa -n mynamespace -o yaml
- apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: 2018-09-08T12:59:17Z
name: example-sa
namespace: mynamespace
resourceVersion: "409327"
...
secrets:
- name: example-sa-token-vmfg6 # 自动分配的secret对象,以Secret对象的方式保存在Etcd中
$ kubeectl get clusterroles
2
3
4
5
6
7
8
9
10
11
12
13
# 如何使用:
注:如果不配置的话,系统会创建一个名为default的ServiceAccount分配给Pod,它有访问APIService的绝大部分权限
apiVersion: v1
kind: Pod
metadata:
namespace: mynamespace
name: sa-token-test
spec:
containers:
- name: nginx
image: nginx:1.7.9
serviceAccountName: example-sa
2
3
4
5
6
7
8
9
10
token会自动挂载到 /var/run/secrets/kubernetes.io/sereviceaccount下
$ kubectl describe pod sa-token-test -n mynamespace
Name: sa-token-test
Namespace: mynamespace
...
Containers:
nginx:
...
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from example-sa-token-vmfg6 (ro)
$ kubectl exec -it sa-token-test -n mynamespace -- /bin/bash
# 它只能做GET WATCH LIST操作,已经绑定了限制
2
3
4
5
6
7
8
9
10
11
基于角色的访问控制(RBAC)。
其实,你现在已经能够理解,所谓角色(Role),其实就是一组权限规则列表。
而我们分配这些权限的方式,就是通过创建 RoleBinding 对象,将被作用者(subject)和权限列表进行绑定。另外,与之对应的 ClusterRole 和 ClusterRoleBinding,则是 Kubernetes 集群级别的 Role 和 RoleBinding,它们的作用范围不受 Namespace 限制。而尽管权限的被作用者可以有很多种(比如,User、Group 等),但在我们平常的使用中,最普遍的用法还是 ServiceAccount。所以,Role + RoleBinding + ServiceAccount 的权限分配方式是你要重点掌握的内容。我们在后面编写和安装各种插件的时候,会经常用到这个组合。
# 27 Operator工作原理
Operator:编程友好的管理“有状态应用”的解决方案