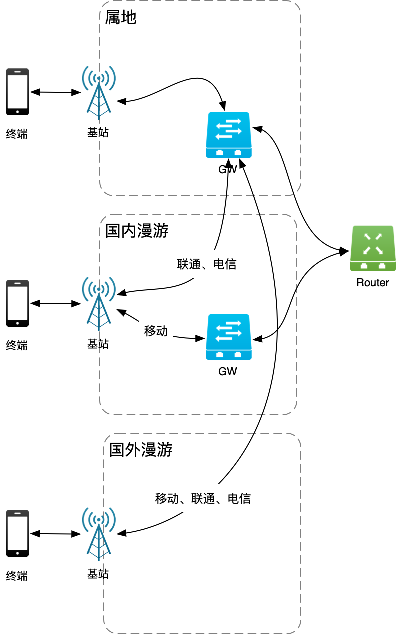
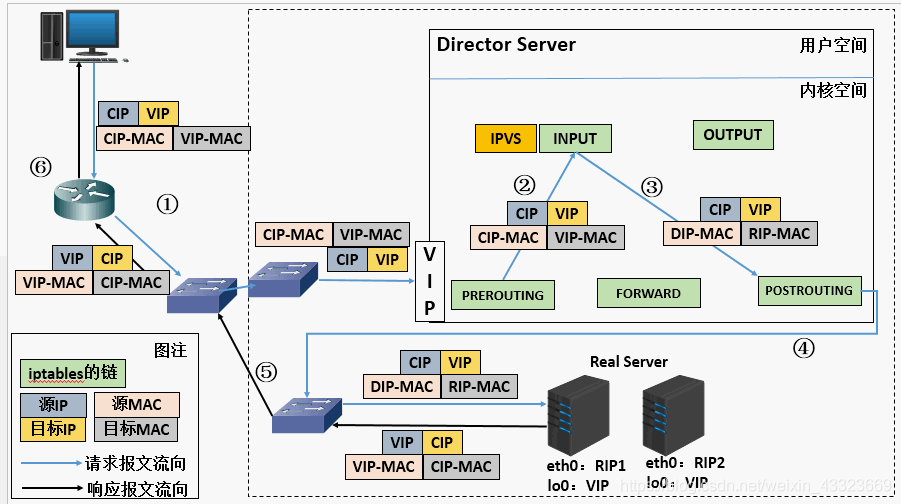
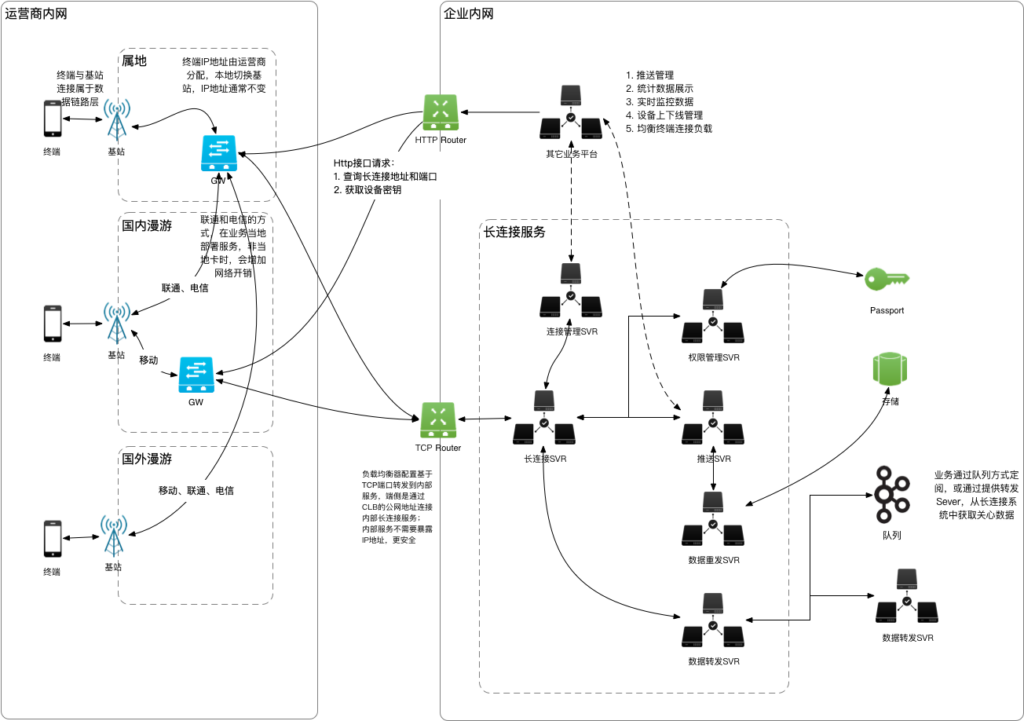
config.yaml
VERSION: 2
OUTPUT_DIR: /data/mooc/data_kiti/src/output
#coding=utf-8
# conda activate leastereo
import glob
import os
import torch
from detectron2.structures import BoxMode
from utils import writexml
import cv2
import numpy as np
from detectron2.engine import DefaultTrainer
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data import build_detection_train_loader
from detectron2.utils.logger import setup_logger
from detectron2.utils.visualizer import Visualizer
setup_logger()
DETECTRON2_REPO_PATH = "/data/mooc/workspace/detectron2/"
KEYS = ['Truck', 'Cyclist', 'Car', 'DontCare', 'Tram', 'Pedestrian', 'Person_sitting', 'Van', 'Misc']
KEYS_DICS = {}
index = 0
for key in KEYS:
KEYS_DICS[key] = index
index += 1
def get_tl_dicts(data_dir):
cates = {}
dataset_dicts = []
list_anno_files = glob.glob(data_dir + "label_2/*")
max_num = 100
for file_path in list_anno_files:
with open(file_path) as f:
max_num = max_num - 1
if max_num < 0:
break
file_name = os.path.basename(file_path) # 000000.txt
simple_name, ext = os.path.splitext(file_name) # 000000 .txt
image_path = data_dir + "image_2/" + simple_name + ".png"
height, width = cv2.imread(image_path).shape[:2]
record = {}
record["file_name"] = image_path
record["height"] = height
record["width"] = width
objs = []
anno_items = f.readlines()
for anno_item in anno_items:
anno_infos = anno_item.split(" ")
if anno_infos[0] == "Misc" or anno_infos[1] == "DontCare":
continue
category = anno_infos[0]
xmin = int(float(anno_infos[4]))
ymin = int(float(anno_infos[5]))
xmax = int(float(anno_infos[6]))
ymax = int(float(anno_infos[7]))
obj = {
"bbox": [xmin, ymin, xmax, ymax],
"bbox_mode": BoxMode.XYXY_ABS,
"category_id": KEYS_DICS[category],
"iscrowd": 0
}
cates[category] = KEYS_DICS[category]
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
# print(cates)
return dataset_dicts
# 打印类别
# {'Truck', 'Cyclist', 'Car', 'DontCare', 'Tram', 'Pedestrian', 'Person_sitting', 'Van', 'Misc'}
# print(get_tl_dicts("/data/mooc/data_kiti/image/training/"))
def register_dataset():
d = "training"
# 注册数据集
DatasetCatalog.register("training_data", lambda d="training":get_tl_dicts("/data/mooc/data_kiti/image/training/"))
# 数据集添加元信息,主要是类别名,用于可视化
MetadataCatalog.get("training_data").set(thing_classes=KEYS) # ["Car"...]
# 添加数据集评估指标,采用coco评测准则
MetadataCatalog.get("training_data").evaluator_type = "coco"
tl_metadata = MetadataCatalog.get("training_data")
return tl_metadata
def train_kiti_data():
# 训练
cfg = get_cfg()
cfg.merge_from_file(DETECTRON2_REPO_PATH + "configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")
cfg.DATASETS.TRAIN = ("training_data",) # 使用数据集
# train_loader = build_detection_train_loader(cfg, mapper=None)
# no metrics implemented for this dataset
# no metrics implemented for this dataset
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
# 从 Model Zoo 中获取预训练模型
# cfg.MODEL.WEIGHTS = "https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl"
# cfg.MODEL.WEIGHTS = "/data/mooc/workspace/detectron2/models/model_final_280758.pkl"
cfg.MODEL.WEIGHTS = "./output/model_final.pth" # initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.01 # 学习率
cfg.SOLVER.MAX_ITER = 300 # 最大迭代次数
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 9
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train() # 开始训练
def get_config():
cfg = get_cfg()
cfg.merge_from_file(DETECTRON2_REPO_PATH + "configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")
cfg.merge_from_file("/data/mooc/data_kiti/src/config.yaml")
print(cfg.OUTPUT_DIR)
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
cfg.MODEL.DEVICE = "cpu"
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.8 # set the testing threshold for this model
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 9
return cfg
def get_predictor(cfg):
predictor = DefaultPredictor(cfg)
return predictor
def testing_kiti_data(cfg, predictor, file_path, tl_metadata):
print(file_path)
# cfg = get_cfg()
# cfg.merge_from_file(DETECTRON2_REPO_PATH + "configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")
# cfg.merge_from_file("/data/mooc/data_kiti/src/config.yaml")
# print(cfg.OUTPUT_DIR)
# cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
# cfg.MODEL.DEVICE = "cpu"
# cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.8 # set the testing threshold for this model
# cfg.MODEL.ROI_HEADS.NUM_CLASSES = 9
# predictor = DefaultPredictor(cfg)
im = cv2.imread(file_path)
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1],
metadata=tl_metadata,
scale=0.8,
)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
ret_m = v.get_image()
file_name = os.path.basename(file_path) # 000000.txt
simple_name, ext = os.path.splitext(file_name) # 000000 .txt
cv2.imencode(".png",ret_m)[1].tofile(cfg.OUTPUT_DIR + "/" + file_name)
cv2.waitKey()
print(outputs)
def im2bytes(im: np.ndarray, ext='.jpg') -> bytes:
return cv2.imencode(ext, im)[1].tobytes()
def bytes2im(buf: bytes) -> np.ndarray:
return cv2.imdecode(np.frombuffer(buf, np.uint8), cv2.IMREAD_COLOR)
if __name__ == '__main__':
metadata = register_dataset()
print("*"*100)
# train_kiti_data()
print("*"*100)
cfg = get_config()
predictor = get_predictor(cfg)
testing_kiti_data(cfg, predictor, "/data/mooc/data_kiti/image/testing/image_2/000001.png", metadata)
testing_kiti_data(cfg, predictor, "/data/mooc/data_kiti/image/testing/image_2/000314.png", metadata)
testing_kiti_data(cfg, predictor, "/data/mooc/data_kiti/image/testing/image_2/000045.png", metadata)
# print("*"*100)
# cfg = get_cfg()
# model = torch.load(os.path.join(cfg.OUTPUT_DIR, "model_final.pth"))
# print(model)