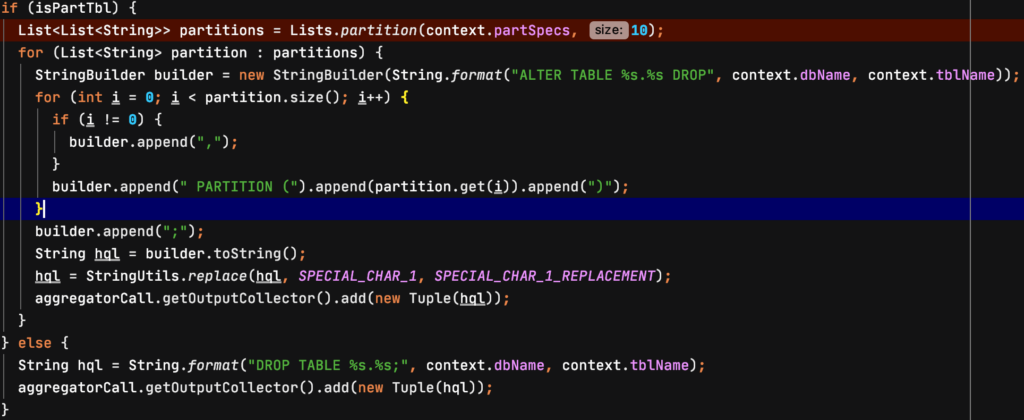
手写了个python+ffmpeg的视频去音轨的脚本,多线程。
- 支持ctrl+关闭程序
- 相对完善的统计数据
# 后台启动
nohup xxx.py &
# 统计处理量
cat cos_process_log.csv |awk ‘{print $1}’ |awk ‘BEGIN{sum=0;count=0;}{sum+=$1;count+=1;}END{print sum / 1024 / 1024 / 1024 “GB ” count}’
283.74GB 5819
# 查询处理进度
tail -f nohup.out
进度:POOL: 5919 START: 5908 FINISH: 5876
# -*- coding=utf-8
from qcloud_cos.cos_client import CosConfig, CosS3Client
import os
from concurrent.futures.thread import ThreadPoolExecutor
import threading
import datetime
from time import sleep
from threading import Thread
import io
from qcloud_cos.cos_exception import CosClientError, CosServiceError
import subprocess
import signal
bucket = 'xxxx-xxxx-111111111'
cos = CosS3Client(
CosConfig(Region='ap-xxxx',
Secret_id='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
Secret_key='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'))
dir_logs = f'/data/mosaic/output/mmpeg'
dir_tmp_files = f'/data/mosaic/output/tmp'
dir_target_files = f'/data/mosaic/output/target'
os.makedirs(dir_logs, exist_ok=True)
os.makedirs(dir_tmp_files, exist_ok=True)
os.makedirs(dir_target_files, exist_ok=True)
start_task_num = 0
finish_task_num = 0
pooled_task_num = 0
task_run_lock = threading.RLock()
executor = ThreadPoolExecutor(max_workers=32,
thread_name_prefix='object_check_')
log_lock = threading.RLock()
cos_process_log_fi = open(dir_logs + '/cos_process_log.csv', mode='a')
cos_erro_log_fi = open(dir_logs + '/cos_erro_log.txt', mode='a')
prefix = '视频/'
prefix_output = '视频-output/'
running_lock = threading.RLock()
running = True
def list_cos_subobject(Prefix="", Marker="") -> ([], [], str, bool):
response = cos.list_objects(Bucket=bucket,
Prefix=Prefix,
Delimiter='/',
Marker=Marker,
MaxKeys=100,
ContentType='text/html; charset=utf-8')
dirs = []
keys = []
if 'CommonPrefixes' in response:
for folder in response['CommonPrefixes']:
dirs.append(folder['Prefix'])
if 'Contents' in response:
for content in response['Contents']:
keys.append(content['Key'])
isTruncated = response['IsTruncated'] == 'true'
nextMarker = ""
if isTruncated:
nextMarker = response['NextMarker']
return (dirs, keys, nextMarker, isTruncated)
def get_obj(bucket: str, key: str, tmp_file: str):
for i in range(0, 10):
try:
response = cos.download_file(Bucket=bucket,
Key=key,
DestFilePath=tmp_file)
break
except CosClientError or CosServiceError as e:
print(e)
def put_obj(bucket: str, key: str, file_path: str):
# with open(file_path, 'rb') as fp:
# response = cos.put_object(Bucket=bucket, Body=fp, Key=key)
# print(response['ETag'])
for i in range(0, 10):
try:
response = cos.upload_file(Bucket=bucket,
Key=key,
LocalFilePath=file_path)
break
except CosClientError or CosServiceError as e:
print(e)
log_lock.acquire()
try:
cos_erro_log_fi.write("%s\t%s\n" % (file_path, key))
cos_erro_log_fi.flush()
finally:
log_lock.release()
def set_not_running():
running_lock.acquire()
try:
global running
running = False
finally:
running_lock.release()
def is_running():
# 停止了后,不再新增加任务
running_lock.acquire()
try:
global running
return running
finally:
running_lock.release()
def is_not_running():
# 停止了后,不再新增加任务
running_lock.acquire()
try:
global running
return not running
finally:
running_lock.release()
def get_pooled_task_num():
task_run_lock.acquire()
try:
global pooled_task_num
return pooled_task_num
finally:
task_run_lock.release()
def inc_pooled_task_num():
# pooled
task_run_lock.acquire()
try:
global pooled_task_num
pooled_task_num += 1
return pooled_task_num
finally:
task_run_lock.release()
def get_start_task_num():
task_run_lock.acquire()
try:
global start_task_num
return start_task_num
finally:
task_run_lock.release()
def inc_start_task_num():
task_run_lock.acquire()
try:
global start_task_num
start_task_num += 1
return start_task_num
finally:
task_run_lock.release()
def inc_finish_task_num():
task_run_lock.acquire()
try:
global finish_task_num
finish_task_num += 1
return finish_task_num
finally:
task_run_lock.release()
def process_one_key(dir: str, key: str, cur_index: int):
if key.endswith('.mp4'):
global dir_logs
global dir_tmp_files
global dir_target_files
#-------------------------------------------------
# if key.endswith('.jpg') and not key.endswith('-des.jpg'):
# tmp_file = key.replace(prefix, dir_tmp_files + "/")
# execd_file = key.replace(prefix, dir_target_files + "/")
_, name = os.path.split(key)
_, ext = os.path.splitext(key)
tmp_file = "%s/%07d%s" % (dir_tmp_files, cur_index, ext)
execd_file = "%s/%07d%s" % (dir_target_files, cur_index, ext)
target_path = key.replace(prefix, prefix_output)
os.makedirs(os.path.dirname(tmp_file), exist_ok=True)
os.makedirs(os.path.dirname(execd_file), exist_ok=True)
if cos.object_exists(Bucket=bucket, Key=target_path):
return
#------------------------------------------------- download
get_obj(bucket, key, tmp_file)
#------------------------------------------------- 处理文件
# 清理旧文件
if dir_target_files in execd_file and os.path.exists(execd_file):
os.remove(execd_file)
# 处理文件
# ffmpeg -i input.mp4 -vcodec copy -an output.mp4
# cmd = "cp %s %s && ls -l %s" % (tmp_file, execd_file, execd_file)
cmd = "ffmpeg -i %s -vcodec copy -an %s && ls -l %s" % (
tmp_file, execd_file, execd_file)
# cmd = "ffmpeg -i %s -vcodec copy -acodec copy %s && ls -l %s" % (tmp_file, execd_file, execd_file)
# os.system("cp %s %s" % (tmp_file, execd_file))
subprocess.call(cmd, shell=True)
# 打印文件日志
#------------------------------------------------- 上传到新cos地址
put_obj(bucket=bucket, key=target_path, file_path=execd_file)
#------------------------------------------------- TODO:打印处理文件的日志
file_stats = os.stat(tmp_file)
file_size = file_stats.st_size
log_lock.acquire()
try:
cos_process_log_fi.write("%s\t%s\n" % (file_size, target_path))
cos_process_log_fi.flush()
finally:
log_lock.release()
# 清理本地文件
if dir_tmp_files in tmp_file and os.path.exists(tmp_file):
os.remove(tmp_file)
if dir_target_files in execd_file and os.path.exists(execd_file):
os.remove(execd_file)
def get_object_meta_target(dir, key):
# 未开始的任务就不用做了
if is_not_running():
return
cur_index = inc_start_task_num()
print("开始处理:%07d %s" % (cur_index, key))
try:
process_one_key(dir, key, cur_index)
except Exception as e:
print(e)
finally:
finish_total = inc_finish_task_num()
print("完成处理:%07d %s 总计:%07d" % (cur_index, key, finish_total))
def check(prefix):
global executor
marker = ""
while True:
(dirs, keys, nextMarker,
isTruncated) = list_cos_subobject(Prefix=prefix, Marker=marker)
# 文件
for key in keys:
if is_not_running():
return
while get_pooled_task_num() - get_start_task_num() > 10:
stat_log_print()
if is_not_running():
return
sleep(1)
inc_pooled_task_num()
# 执行任务
executor.submit(get_object_meta_target, prefix, key)
# 目录
for dir in dirs:
check(dir)
# 是否处理完
if not isTruncated:
break
# 下一步
marker = nextMarker
def onSig(signo, frame):
set_not_running()
pass
def stat_log_print():
global pooled_task_num
global start_task_num
global finish_task_num
print("进度:POOL: %5d START: %5d FINISH: %5d" %
(pooled_task_num, start_task_num, finish_task_num))
if __name__ == "__main__":
# signal.signal(signal.SIGCHLD, onSigChld)
signal.signal(signal.SIGINT, onSig)
signal.signal(signal.SIGTERM, onSig)
check(prefix)
while (True):
# 判断是否处理完
stat_log_print()
pre_start_task_num = start_task_num
if pre_start_task_num == 0:
continue
if pre_start_task_num == finish_task_num:
sleep(10)
if pre_start_task_num == start_task_num:
break
sleep(1)
print("finish")
# cat cos_process_log.csv |awk '{print $1}' |awk 'BEGIN{sum=0;count=0;}{sum+=$1;count+=1;}END{print sum / 1024 / 1024 / 1024 "GB " count}'