
Understanding Indexing
Without Needing to Understand Data Structures
MySQL UC 2011 – April 12, 2011
Zardosht Kasheff
什么是表?
(key,value)对集合的词典
- 确保你可以 修改 这个词典(插入、删除、修改)和 查询(点查询、范围查询)词典
- B-Tree和Fractal Tree是两个词典的例子
- 哈希则不是(不支持范围查询)
例子:
CREATE TABLE foo (a INT, b INT, c INT, PRIMARY KEY(a));
然后我们插入一批数据
| a | b | c |
|---|---|---|
| 100 | 5 | 45 |
| 101 | 92 | 2 |
| 156 | 56 | 45 |
| 165 | 6 | 2 |
| 198 | 202 | 56 |
| 206 | 23 | 252 |
| 256 | 56 | 2 |
| 412 | 43 | 45 |
一个key定义了词典的排序规则
1、对于数据结构和存储引擎我们会认为,在排序上进行范围查询是 快速 的
2、在其它顺序上的范围查询会进行表的扫描,这个操作是 很慢 的
3、点查询需要检索一个特定的值也是 慢 的
一个点查询是快速的,但是读取一批行用这种方法会比使用按顺序的范围查询慢2个数量级词典 T 上的索引 I 也是一个词典
1、同样我们需要定义一个(key,value)对
2、索引上的key是主词典上的列的子集
3、索引I的值是T的主KEY
还有其它的方法去定义这个值,但我们还是坚持使用T的主KEY来定义这个值
例子:
ALTER TABLE foo ADD KEY(b);
然后我们得到
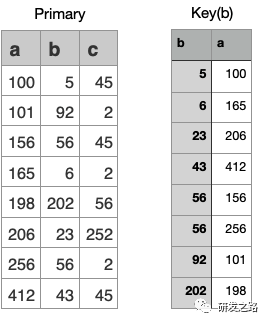
问题:COUNT( * ) WHERE a<120;
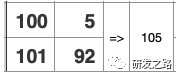
问题:COUNT( * ) WHERE b>50;
问题:SUM( c ) WHERE b >50;
索引的好处?
1、索引使得查询变得快速
索引会提升部分查询请求的速度2、需要在心里根据查询设计索引
选出最重要的查询给它们设计索引
考虑索引本身的代价设计一个好的索引有3个规则可以参考
1、避免任何数据结构的细节
B树和分形树对于计算机科学家来说是有趣和好玩的,但这三个规则同样适用于其它数据结构
所有我们需要考虑的是范围查询是快速的(对每行)而点查询则慢的多(对行)2、世界上没有绝对的规则
索引像是一个数据问题
规则有帮助,但每个方案都有自己的问题,需要分析解决问题的方法3、也就是说规则有很大的帮助
三个规则
1、查询较少的数据
少的带宽,少的处理…2、减少点查询
数据访问成本是不一样的
顺序访问数据比无序访问 **快的多**3、避免排序
GROUP BY和ORDER BY查询需要后期的检索工作
索引在这种查询中可以帮助获得RowID我们来分别看下这三种规则
规则1:查询较少的数据
Rule1:慢查询的例子
表:(100万行数据,没有索引)
CREATE TABLE foo (a INT, b INT, c INT);
查询(匹配1000行数据)
SELECT SUM(c) FROM foo WHERE b=10 and a<150;
查询计划:
行b=10 AND a<150可以在表的任何地方
没有索引的帮助,整个表都会被扫描执行速度慢:
检索100万行数据仅仅查询1000行数据
Rule1:如何去添加一个索引
1、我们应该怎么去做?
减少检索到的数据
分析远少于100万的数据行2、怎样做(对于一个简单的查询)?
设计索引时着眼于WHERE子句
由查询关注那些行来决定
其它行的数据对于这个查询来说并不重要对于查询 SELECT SUM( c ) FROM foo WHERE b=10 and a<150;
Rule1:那个索引?
选择1:Key(a)
选择2:Key(b)
那个更好?由select来决定:
如果WHERE a<150的数据行更少,key(a)更好
如果WHERE b=10的数据更少,key(b)更好选择3:key(a) AND key(b),然后MERGE我们稍后会进行讨论
Rule1:选择最好的索引
key(a)与key(b)都不是最佳的
考虑:
- WHERE a<150有20万行数据
- WHERE b=10有10万行数据
- WHERE b=10 AND a<150有1000行数据
然后key(a)和key(b)都会检查很多的数据
为了获得更好的性能,索引必须尝试尽量优化WHERE条件
我们需要复合索引复合索引可以减少数据检索
WHERE条件:b=5 AND a<150
选择1:key(a, b)
选择2:key(b, a)问题又来了那种选择更好?
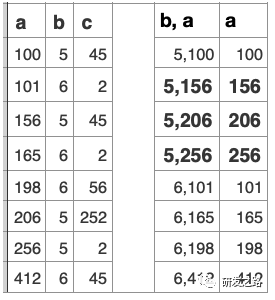
Key(b, a)!索引规则:
当创建一个复合索引,需要对每个列进行检查,条件b是相等判断,但在a上不是。
问题:WHERE b=5 and a>150;
复合索引:没有平等的条件
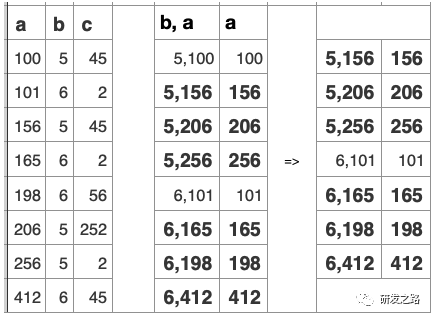
如果WHERE条件是这样的:
WHERE a>100 AND a<200 AND b>100;
那个更好?
key(a),key(b),key(a,b),key(b,a)?
索引规则:
只要复合索引不被用于相等查询,复合索引的其它部分不会减少数据检索量
key(a,b)不再比key(a)好
key(b,a)不再比key(b)好
问题:WHERE b>=5 AND a>150;
复合索引:另一个例子
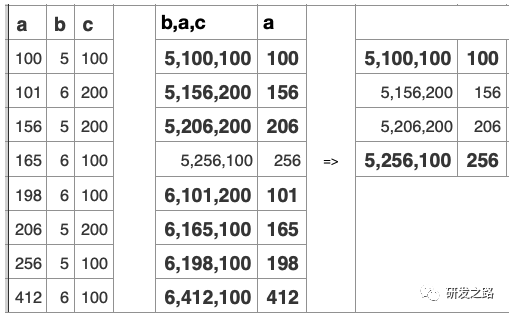
WHERE条件:b=5 AND c=100
key(b,a,c)和key(b)一样好
因为a没有在条件中使用,所以在索引中包含c并不会有帮助,key(b,c,a)会更好
规则1:总结
根据查询条件设计复合索引
把相等条件的查询列放在复合索引的开始位置
保证第一个非相等条件的列在索引中越有选择性越好
如果复合索引的第一个列没有被相等条件来使用,或者没有在条件中使用,复合索引的其它列对于减少数据的检索没有帮助
是否就表明它们是无用的呢?
它们在规则2中可能有用规则2:避免点查询
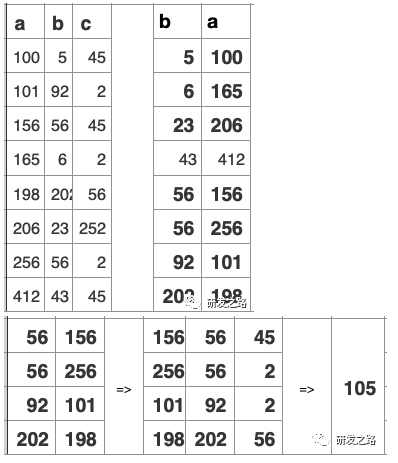
表:
CREATE TABLE foo (a INT,b INT,c INT,PRIMARY KEY(a), KEY(b);
查询:
SELECT SUM( c ) FROM foo WHERE b>50;
查询计划:使用key(b)
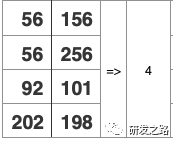
因为随机的点查询的原因,对每个行都进行检索的代价很大问题:SUM( c ) WHERE b>50;
还是这张表,但查询计划不同了
SUM(c) WEHRE b>50;查询计划:扫描主表
每行的检索成本低
但是需要检索很多行问题:SUM( c ) WEHRE b>50;
如果我们添加了另一个索引会怎么样?
如果添加key(b, c)呢?
由于我们在b上有索引,我们只检索我们需要的行
由于索引包含C的信息,我们不再需要再去检索主表了。 **没有点查询了**覆盖索引:索引覆盖一个查询,如果这个索引包含足够的信息来回答这个查询。
例子:
问:SELECT SUM( c ) FROM foo WHERE b<100;
问:SELECT SUM( b ) FROM foo WHERE b<100;
索引:
key(b, c): 对第一个查询是覆盖索引
key(b, d):对第二个查询是覆盖索引
key(b, c, d):对每个索引都是覆盖索引
如何去构建一个覆盖索引
把检索的每个列都包含进去,并不仅仅是查询条件
问:SELECT c,d FROM foo WHERE a=10 AND b=100;
错误:ADD INDEX(a, b)
并不是覆盖索引。仍然需要点查询去检索c和d的值正确:ADD INDEX(a, b, c, d)
包含所有相关的列
按照规则1规定把 a 和 b 放在索引开始位置如果主键匹配WHERE条件呢?
问题:SELECT sum(c) FROM foo WHERE b>100 AND b<200;
SCHEMA:CREATE table foo (a INT, b INT, c INT, ai INT AUTO_INCREMENT, PRIMARY key(b, ai));
查询在主词典上做了范围查询
只有一个词典会按顺序访问到
这个查询很快
主键覆盖所有查询
如果排序规则匹配查询条件,问题得到解决什么是聚簇索引
如果主键不匹配查询条件呢?
理想的情况下,必须确保辅助索引包含所有列
存储引擎不会让你去这样做
有一个例外。。。。TokuDB可以
TokuDB允许你定义任何聚簇索引
一个聚簇索引包含所有的查询,就像主键做的一样聚簇索引的实践
问:SELECT SUM(c) FROM foo WHERE b<100;
问:SELECT SUM(b) FROM foo WEHRE b>200;
问:SELECT c,e FROM foo WEHRE b=1000;
索引:
key(b, c):第一个查询
key(b, d):第二个查询
key(b, c, e):第一个和第三个查询
key(b, c, d, e):所有的三个查询
索引需要大量的查询分析
考虑那个会涵盖所有的查询:
聚簇索引 b
聚簇索引可以让你更加关注于查询条件
它们减少了点查询并且使查询更加快聚簇索引更多的信息:索引合并
例子:
CREATE TABLE foo (a INT, b INT, c INT); SELECT SUM(c) FROM foo WHERE b=10 AND a<150;
假设:
a<150有20万行数据
b=10有10万行数据
b=10 AND a<150有1000行数据
如果我们使用key(a)和key(b)然后把结果集合合并会怎样?
合并计划:
查询20万行数据从key(a)中,where a<150
查询10万行数据从key(b)中,where b=10
合并结果集合,然后找到查询标识的1000行数据
执行1000行数据的点查询去得到c
这比没有索引好一点
和没有索引相比,减少了扫描行的数量
和没有合并相比,减少了点查询的数量那么聚簇索引会对合并有帮助么?
考虑key(a)是个聚簇索引
查询计划:
扫描key(a)20万行数据,where a<150
扫描结果集合得到b=10的结果
使用得到的1000行的数据去检索C的值
一次得到,没有点查询
更好的选择还有没有?
聚簇索引(b, a)!规则2总结:
避免点查询
确保索引覆盖查询
包含查询涉及到的所有列,并不仅仅是查询条件中的使用聚簇索引
使用聚簇索引包含所有查询
允许用户把关注点集中在查询条件上
给多个查询提速,包括还没有预见到的查询--简化数据库设计规则3:避免排序
简单的查询不需要后续的处理
select * from foo where b=100;
仅仅取得数据然后返回给用户
复杂的查询需要对数据进行后续的处理
GROUP BY 和 ORDER BY 会排序数据
选择正确的索引可以避免这些排序的步骤
考虑:
问:SELECT COUNT(c) FROM foo;
问:SELECT COUNT(c) FROM foo GROUP BY b, ORDER BY b;
查询计划1:
当进行表扫描时,给C计数
查询计划2:
扫描表把数据写到临时表中
对临时表按B进行排序
重新扫描排序后的数据,对每个b,使用c进行计数
如果我们使用key(b, c)会怎么样呢?
通过添加国所有需要的字段,我们覆盖了查询。 快速
通过提前对B进行排序,我们避免了排序 快速
总结:
通过给GROUP BY或者ORDER BY使用预先排序了的索引把它们都放到一起:
简单查询
*
SELECT COUNT(
) FROM foo WHERE c=5, ORDER BY b;**
key(c, b):
把c放在索引第一个位置去减少行检索 R1
然后通过剩余的行排序去避免排序 R3
因为相等的检查在c上,所以剩余的行数据会被按b排好序
SELECT SUM(d) FROM foo WHERE c=100, GROUP BY b;
key(c, b, d):
c在索引的第一个位置可以减少行数据的检索 R1
然后其它的数据在b上排好序去避免查询 R3
确保了查询覆盖所有的查询,避免了点查询 R2在一些情况下,并没有明确的答案
最优的索引是和数据相关的*
问:SELECT COUNT(
) FROM foo WHERE c<100, GROUP BY b;**
索引:
key(c, b)
key(b, c)
key(c, b)的查询计划:
使用c<100对数据进行过滤
仍然需要对数据进行排序
*检索的行不会被b进行排序
*查询条件不需要对c进行相等的检查,因此b的值分布在不同的c值块中
key(b, c)的查询计划
按b进行排序,R3
列WHERE c>=100同样需要处理,因此没有R1的优势那个更好一些呢?
答案依赖于数据是什么样的
如果c>=100有更多的数据,节省时间不去检索无用的行。使用key(c, b)
如果c>=100没有多少行,执行查询的时间是以排序为主,那么使用key(b, c)
问题的关键是,通常情况下,规则会有帮助,但它通常只是帮助我们去思考查询和索引,而不是给我们一个配方。
另一个重要的问题:为什么不把所有的加载都添加上索引呢?
需要跟上插入的负荷更多的索引 = 更小的系统负荷
索引的代价:
空间:
问题
每个索引都会增加存储的需求
选项
使用压缩性能:
问题
B-trees在某些索引任务中执行的很快(内存中,顺序的key),但是在其它类型的索引(辅助索引)会慢20倍
选项
分形树索引对于所有的索引类型都很快速
很容易索引
可经常索引范围查询性能:
问题
规则2依赖于范围查询足够快
B-tree会比较容易碎片化(删除、随机插入…),碎片化的B-tee在范围查询上会变慢
选项
对于B-tee可以优化表,导出然后导入(时间和离线)
对于Fractal Tree索引,不是问题,它不会碎片化
PS. 文档翻译自:
Understanding Indexing
Without Needing to Understand Data Structures
MySQL UC 2011 – April 12, 2011
Zardosht Kasheff
For more information…
• Please contact me at [email protected] for any
thoughts or feedback
• Please visit
Tokutek.com
for a copy of this presentation
to learn more about the power of indexing, read about
Fractal Tree indexes, or to download a free eval copy of
TokuDB
PS. 正确设计数据库索引并不只是DBA的事情,每个合格开发者都必须具备这样的能力,但最近老是发现乱使用索引和不使用索引的情况,很明显是不理解索引,希望这篇译文能够帮助到这部分开发者吧。另外还有一篇不错的文章,有时间也会翻译出来,敬请期待。