功能
当前线上系统情况:
- hadoop集群小文件数太多
- hive的meta存储压力,有hive分区表有75W+分区
- 释放非必要存储资源,中间层的数据较容易重新生成
- 规范业务Hive使用,数据治理
名词:
路径不规范:
- 库路径无重合
- 库路径下不能有其它库
- 库路径必须在库所有者目录(/user/{Database.getOwnerName()}/…)下
- 表是在所在库路径下
- 表路径下不能有其它库
- 表路径下不能有其它表
- 表路径必须在表所有者目录(/user/{Table.getOwnerName()}/…)下
TTL: 数据保留时间(单位:天)
LEVEL:数据级别(0:永久保留;1:需要进行生命周期)
需要实现的功能:
- 新建表将纳入生命周期,增加库表TTL和LEVEL的设置功能
- 新建表未指定生命周期会使用默认值,默认生命周期会删除60天前未更新的数据,除非新建表对应的库设置了生命周期,此种情况下,新建表会继承对应库的生命周期,建议创建表时设置,避免数据误删除;配置方式:CREATE EXTERNAL TABLE
guoguo.t_test_02(idstring) … TBLPROPERTIES (‘LEVEL’=’1′,’TTL’=’70’) - 配置了生命周期的非分区表到期会Drop表,分区表则只Drop分区
- 判断数据更新时间的标准是:
- 1)表分区元数据更新时间,2)表分区对应的hdfs数据更新时间
- 取两者的最大值做为数据更新的时间
- 生命周期清理数据时基于数据更新时间后推ttl天清理
- 数据安全方案
- 邮件:执行删除前一周会分别和库、表的所有者发送其负责的待删除的库、表的通知
- 邮件:执行日报,每天把当天执行的情况汇总按需发给管理员,库所有者,表所有者
- 邮件:路径不规范的库和表,不会进行处理,并每天有报警邮件,会给相关负责人发送,提醒业务整改
- 备份:清理数据是先移动数据到每天生成的一个处理备份目录,然后再清理元数据
- hive有内部表和外部表之分,内部表删除会影响内部表的元数据和底层数据存储,为保持处理一致,不采用只删除元数据,到期再清理数据的方案
- 移动数据会把meta信息和权限信息一同带到备份目录
- 备份的目录在15天后由程序删除,删除后数据无法恢复
- 恢复:可按天恢复数据和meta信息
- 恢复脚本随每次处理的同时由MR程序生成,保存在HDFS文件中
- 严格的配置和管理权限,普通用户无法修改生命周期配置信息
- 配置权限
- 创建库、创建表的用户权限
- 普通用户无法修改库、表的生命周期属性,只能由配置的管理员账号修改
生命周期配置
增加生命周期默认配置项,表的参数 level=0代表永不过期,默认level=1,数据60天后删除;库的参数level和ttl做为库下面新建表的默认生命周期参数;
METASTORE_LIFE_CYCLE_ADMINS("hive.lifecycle.admins", "admin,hadoop",
"lifecycle admin users."),
METASTORE_LIFE_CYCLE_DEFAULT_LEVEL("hive.lifecycle.default.level", "1",
"lifecycle default level."),
METASTORE_LIFE_CYCLE_DEFAULT_TTL("hive.lifecycle.default.ttl", "60",
"lifecycle default ttl."),
增加生命周期的MetaStorePreEventListener实现,校验参数、权限检查和处理生命周期参数。配置信息保存在Database和Table的Parameters中;
@Override
public void onEvent(PreEventContext context) throws MetaException, NoSuchObjectException, InvalidOperationException {
// 判断操作类型
if (context.getEventType() == PreEventContext.PreEventType.CREATE_DATABASE) {
onPreCreateDatabase(context);
} else if (context.getEventType() == PreEventContext.PreEventType.CREATE_TABLE) {
onPreCreateTable(context);
} else if (context.getEventType() == PreEventContext.PreEventType.ALTER_DATABASE) {
onPreAlterDatabase(context);
} else if (context.getEventType() == PreEventContext.PreEventType.ALTER_TABLE) {
onPreAlterTable(context);
} else if (context.getEventType() == PreEventContext.PreEventType.DROP_DATABASE) {
onPreDropDatabase((PreDropDatabaseEvent) context);// /*do nothing*/
} else if (context.getEventType() == PreEventContext.PreEventType.DROP_TABLE) {
onPreDropTable((PreDropTableEvent) context);// /*do nothing*/
}
}
执行逻辑:
Step 0: 创建MetaStore连接池,并获取db,table列表
产出:[{dbname,tblName}]Step 1: 查询库表信息,并检查是否规范
不规范类型:
case HAS_OTHER_DB:
return String.format("路径中存在其它库%s;", values);
case OWNER_PATH_FAIL:
return String.format("路径与库表所有者不一致%s;", values);
case HAS_OTHER_DB_TBL:
return String.format("路径下其它库的表%s;", values);
case DB_PATH_FAIL:
return String.format("库路径不规范%s;", values);
case HAS_OTHER_TBL:
return String.format("路径下有其它表%s;", values);
case PART_PATH_NOT_IN_TBL:
return String.format("分区不在表路径下%s;", values);
case TBL_NOT_SUB_DB:
return String.format("表路径不在库路径下%s;", values);
检查库表规范
1. 检查库规范,获取库信息,维护DeniedResion
库规范: /user/{Database.getOwnerName()}/…
- 检查库路径是否在库所有者下
- 检查库路径无重合
库信息DatabaseData:
- 库名
- 库所有者
- 库路径是否正确
- NoScamaLocation
- Location(database.getLocationUri())
2. 检查视图规范(ToDo:)
3. 检查表规范,获取表信息,维护DeniedResion
表规范:/user/{table.getOwner}/…
- 检查表是否在库路径下
- 检查表路径下是否有其它库
- 检查表路径下是否有其它表
- 检查表路径是否在表所有者下
表信息TblData:
- 库名
- 表名
- 表所有者(table.getOwner())
- 表类型(table.getTableType())
- 表分区key列表(table.getPartitionKeys().getName())
- 表修改时间(params.get(TRANSIENT_LASTDDLTIME)*1000)
- 表是否使用生命周期
- 从params中获取表级别:level=0 level=1
- 从params表过期时间:ttl 单位天
- 表路径是否正确
- NoScamaLocation
- Location(database.getLocationUri())
4. 检查分区规范
分区必须在表下
产出:
- [DatabaseData] [TblData]
Step 3: 发送库表不规范日报
使用Velocity模板,生成日报表格,发送邮件给hive管理员组
- 库名
- 库所有者
- 库路径
- 不规范原因
- 库管理员(元数据平台管理)
- 报表生成时间
Step 4: Start Write Source File
表和分区路径对应信息写入hdfs,为过期检查做准备
分区表:
创建jdbc连接,从数据库中查询每个规范的分区表的分区信息
String sql = "" +
"SELECT " +
" pt.PART_ID AS PART_ID," +
" ls.LOCATION AS LOCATION," +
" pt.CREATE_TIME AS CREATE_TIME," +
" ptp.PARAM_VALUE AS LAST_DDL_TIME" +
" FROM " +
" (SELECT db.DB_ID FROM DBS AS db WHERE db.name=:db_name) AS db2" +
" INNER JOIN TBLS AS tbl ON (db2.DB_ID = tbl.DB_ID AND tbl.TBL_NAME=:tbl_name)" +
" INNER JOIN PARTITIONS AS pt ON (pt.TBL_ID = tbl.TBL_ID)" +
" LEFT JOIN SDS AS ls ON ( ls.SD_ID = pt.SD_ID )" +
" LEFT JOIN PARTITION_PARAMS AS ptp ON (pt.PART_ID = ptp.PART_ID AND ptp.PARAM_KEY = 'transient_lastDdlTime')";
MapSqlParameterSource paramSource = new MapSqlParameterSource();
paramSource.addValue("db_name", dbName);
paramSource.addValue("tbl_name", tblName);
根据PART_ID查询PART_KEY_VAL信息
StringBuilder builder = new StringBuilder("");
builder.append(" SELECT PART_ID,PART_KEY_VAL ");
builder.append(" FROM PARTITION_KEY_VALS ");
builder.append(" WHERE PART_ID IN (");
List<Long> ids = Lists.transform(datas, new Function<PartDetailEntity, Long>() {
public Long apply(PartDetailEntity entity) {
return entity.getId();
}
});
builder.append(StringUtils.join(ids, ','));
builder.append(")");
builder.append(" ORDER BY PART_ID,INTEGER_IDX");
合并结果集
partitions = [PartDetailEntity{id,location,List<String> values, createTime, lastDdlTime}]分区信息写入hdfs,内容:
- 库名
- 表名
- 表类型
- level
- ttl
- partSpecs
- 路径=partition.getLocation()
- LocType=PARTITION
- 规范:true
- 最后一次修改时间:partition.getLastDdlTime()
非分区表:
信息写入HDFS,内容:
- 库名
- 表名
- 表类型
- ttl
- level
- PartSpecs=null
- location=tblData.getLocation()
- locType=TABLE
- 规范:true
- 库名
- 表名
- 表类型
- level
- ttl
- partSpecs
- 路径=partition.getLocation()
- LocType=PARTITION
- 规范:true
- 最后一次修改时间:tblData.getHiveDdlTime()
Step 5: 过期检查
基于MapReduce实现,读取每条表、分区信息,检查数据更新时间
判断数据是否更新的标准是:1)表分区元数据是否有更新,2)表分区对应的hdfs数据是否有更新
- 修改时间:Max.(fileSystem.getFileStatus().getModificationTime(), 最后一次修改时间) + 1
- 清理时间:修改时间 + ttl * D_1
会根据数据情况分下面三类,写入不同文件中
- 本次会清理
- 将于近期清理
- 本次无需要关注
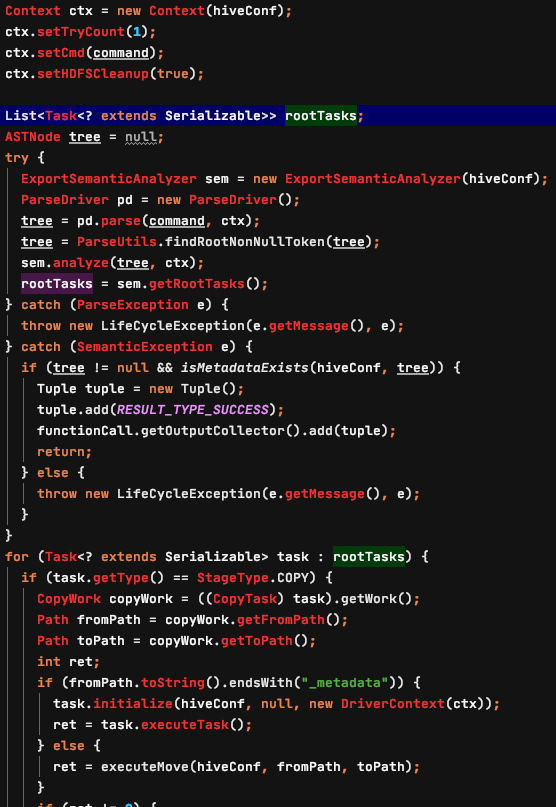
Step 6: Start Gen Export And Drop Cmd

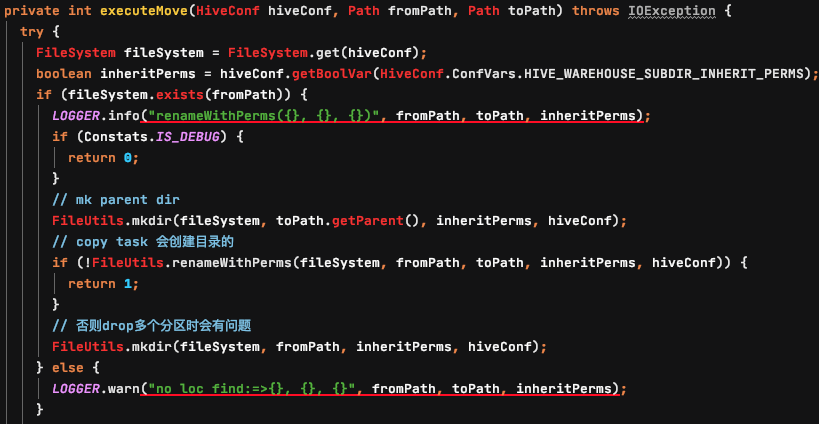
Step 7: 备份数据
备份数据基于MR实现,代码首先获取上一个MR程序生成的Export语句,然后调用hive的底层代码生成执行计划,执行;
使用这种方式在数据需要恢复时,执行恢复后数据的权限不会发生变化
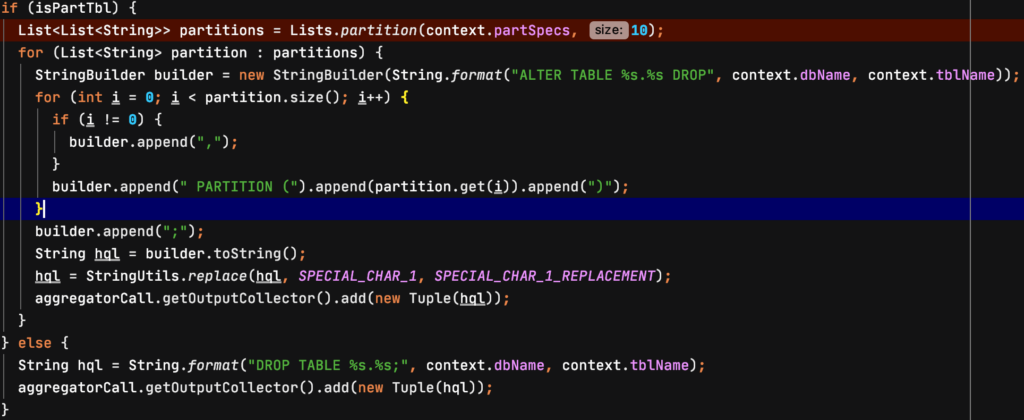
Step 8: 生成清理分区和表的脚本
对于分区表,修改表结构删除分区,对于非分区表,直接删除表
Step 8: Start Exec Drop Hql Cmds
使用MapReduce程序跑清理脚本,
- 拉取执行脚本到本地
- hive -f 执行清理脚本
state = shellCmdExecutor.exec(
String.format("hive -f %s", tmpFile.getAbsolutePath()),
systemEnv, workDir, Constats.IS_DEBUG);Step 9: 生成通知邮件
使用MapperReduce聚合处理数据
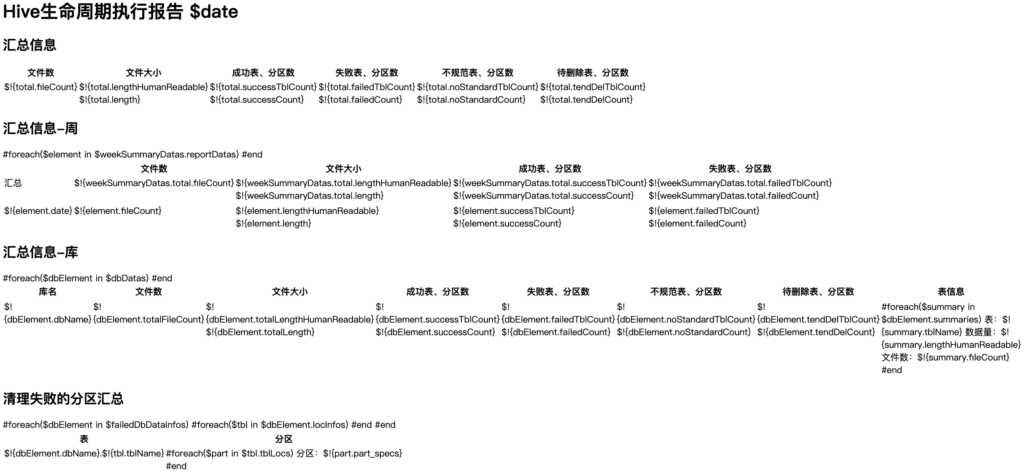
Step 10: 汇总通知
- 库所有者
- 执行失败的库表(忽略)
- 本次成功处理的表、分区
- 将要清理的表、分区
- 不规范的表和分区
- hive管理员邮件组
- 文件统计
- 执行分区统计
- 执行表统计
- 路径统计