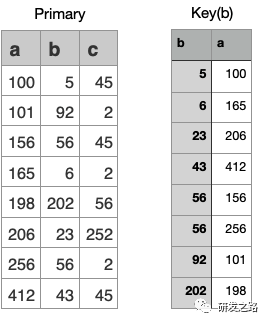
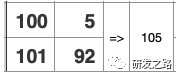
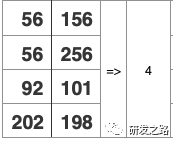
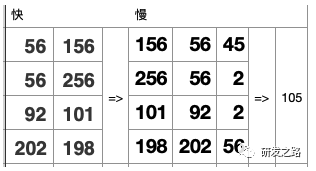
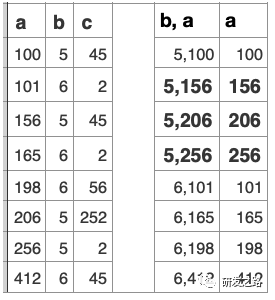
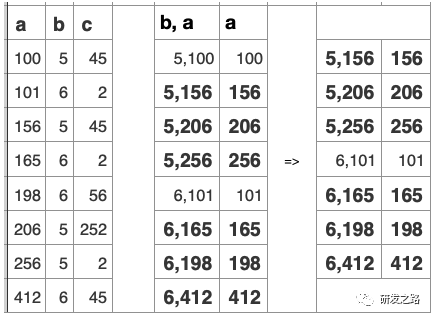
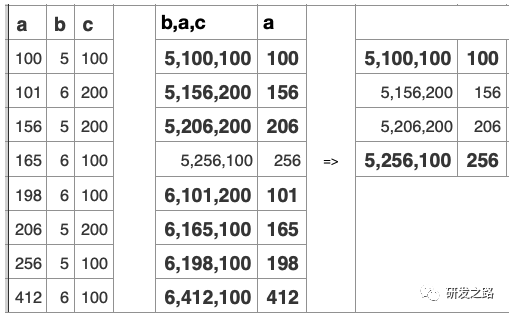
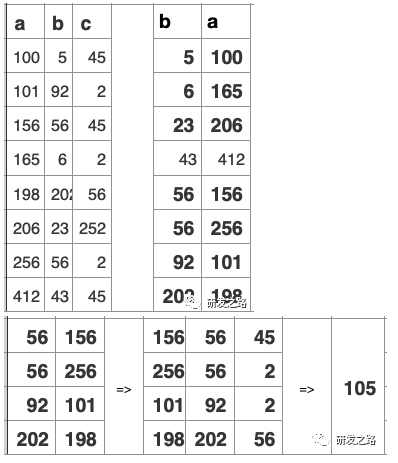
5.1纪元管理 纪元模型:纪元包含给定时间窗口所有提交了的事务 Last Good Epoch:所有数据都成功从WOS移动到ROS Ancient History Mark: 5.2宽容失败 Vertica的数据复制通过使用Projection分段机制,以提供容错 每个Projection,必须至少有一个伙伴projection含有相同的列和分割以确保任何行被存储在同一样节点的Projection,当节点故障,伙伴projection会做为故障节点的源。 不需要传统的事务日志,数据+纪元自己就做为过去系统活动日志。vertica使用这些历史数据,去重放节点丢失的DML。节点会从正常的伙伴projection数据段恢复数据, 恢复,更新,重新平衡和备份都是在线操作;在执行这些操作同时可进行数据的加载和查询。影响的只是计算和带宽资源。
set nocompatible " be iMproved, required
filetype off " required
" set the runtime path to include Vundle and initialize
set rtp+=~/.vim/bundle/vundle/
call vundle#rc()
" alternatively, pass a path where Vundle should install plugins
"let path = '~/some/path/here'
"call vundle#rc(path)
" let Vundle manage Vundle, required
Plugin 'gmarik/vundle'
" The following are examples of different formats supported.
" Keep Plugin commands between here and filetype plugin indent on.
" scripts on GitHub repos
Plugin 'tpope/vim-fugitive'
Plugin 'Lokaltog/vim-easymotion'
Plugin 'tpope/vim-rails.git'
" The sparkup vim script is in a subdirectory of this repo called vim.
" Pass the path to set the runtimepath properly.
Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
" scripts from http://vim-scripts.org/vim/scripts.html
Plugin 'L9'
Plugin 'FuzzyFinder'
" scripts not on GitHub
Plugin 'git://git.wincent.com/command-t.git'
" git repos on your local machine (i.e. when working on your own plugin)
Plugin 'file:///home/gmarik/path/to/plugin'
" ...
filetype plugin indent on " required
" To ignore plugin indent changes, instead use:
"filetype plugin on
"
" Brief help
" : PluginList - list configured plugins
" : PluginInstall(!) - install (update) plugins
" : PluginSearch(!) foo - search (or refresh cache first) for foo
" : PluginClean(!) - confirm (or auto-approve) removal of unused plugins
"
" see :h vundle for more details or wiki for FAQ
" NOTE: comments after Plugin commands are not allowed.
" Put your stuff after this line
Install Plugins
Launch vim and run
: PluginInstall
或者
In command line:
vim +PluginInstall +qall 3、官方vim-lang插件
Config vim file .vimrc,Add content bellow in bottom of the file
" 官方的插件
" Some Linux distributions set filetype in /etc/vimrc.
" Clear filetype flags before changing runtimepath to force Vim to
" reload them.
filetype off
filetype plugin indent off
set runtimepath+=$GOROOT/misc/vim
filetype plugin indent on
syntax on
autocmd FileType go autocmd BufWritePre Fmt
Set up gocode Then you need to get the appropriate version of the gocode, for 6g/8g/5g compiler you can do this: Then you need to get the appropriate go get -u github.com/nsf/gocode (-u flag for “update”)
Configure vim in .vimrc file
Plugin 'nsf/gocode', {'rtp': 'vim/'}
Install Plugins Launch vim and run
: PluginInstall
或者 In command line:
vim +PluginInstall +qall
写一个helloword程序,输入fmt后按如果能看到函数的声明展示出来,说明安装是正确的。
4、代码跳转提示godef Set up godef
go get -v code.google.com/p/rog-go/exp/cmd/godef
go install -v code.google.com/p/rog-go/exp/cmd/godef
git clone https://github.com/dgryski/vim-godef ~/.vim/bundle/vim-godef
" 插件管理器 vundle
set nocompatible " be iMproved, required
filetype off " required
" set the runtime path to include Vundle and initialize
set rtp+=~/.vim/bundle/vundle/
call vundle#rc()
" alternatively, pass a path where Vundle should install plugins
"let path = '~/some/path/here'
"call vundle#rc(path)
" let Vundle manage Vundle, required
Plugin 'gmarik/vundle'
" The following are examples of different formats supported.
" Keep Plugin commands between here and filetype plugin indent on.
" scripts on GitHub repos
" Plugin 'tpope/vim-fugitive'
" Plugin 'Lokaltog/vim-easymotion'
" Plugin 'tpope/vim-rails.git'
" The sparkup vim script is in a subdirectory of this repo called vim.
" Pass the path to set the runtimepath properly.
" Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
" scripts from http://vim-scripts.org/vim/scripts.html
" Plugin 'L9'
" Plugin 'FuzzyFinder'
" scripts not on GitHub
" Plugin 'git://git.wincent.com/command-t.git'
" git repos on your local machine (i.e. when working on your own plugin)
" Plugin 'file:///home/gmarik/path/to/plugin'
" ...
"
filetype plugin indent on " required
" To ignore plugin indent changes, instead use:
" filetype plugin on
"
" Brief help
" : PluginList - list configured plugins
" : PluginInstall(!) - install (update) plugins
" : PluginSearch(!) foo - search (or refresh cache first) for foo
" : PluginClean(!) - confirm (or auto-approve) removal of unused plugins
"
" see :h vundle for more details or wiki for FAQ
" NOTE: comments after Plugin commands are not allowed.
" Put your stuff after this line
syntax on
" ********************************************************************
" 这里省略了其它不相关的插件
" vimgdb插件
run macros/gdb_mappings.vim
" 官方的插件
" Some Linux distributions set filetype in /etc/vimrc.
" Clear filetype flags before changing runtimepath to force Vim to
" reload them.
filetype off
filetype plugin indent off
set runtimepath+=$GOROOT/misc/vim
filetype plugin indent on
syntax on
autocmd FileType go autocmd BufWritePre <buffer> Fmt
" 代码补全的插件
Bundle 'Blackrush/vim-gocode'
" 代码跳转提示
Bundle 'dgryski/vim-godef'
" 代码结构提示
Bundle 'majutsushi/tagbar'
nmap <F8> :TagbarToggle<CR>
let g:tagbar_type_go = {
\ 'ctagstype' : 'go',
\ 'kinds' : [
\ 'p:package',
\ 'i:imports:1',
\ 'c:constants',
\ 'v:variables',
\ 't:types',
\ 'n:interfaces',
\ 'w:fields',
\ 'e:embedded',
\ 'm:methods',
\ 'r:constructor',
\ 'f:functions'
\ ],
\ 'sro' : '.',
\ 'kind2scope' : {
\ 't' : 'ctype',
\ 'n' : 'ntype'
\ },
\ 'scope2kind' : {
\ 'ctype' : 't',
\ 'ntype' : 'n'
\ },
\ 'ctagsbin' : 'gotags',
\ 'ctagsargs' : '-sort -silent'
\ }
cd jpeg-6b
./configure --enable-shared --enable-static
make && make install
# 报错,提示找不到文件 /usr/local/man/man1/
# mkdir -p /usr/local/man/man1/ 然后再执行 make install
cd libpng-1.5.12
./configure
make && make install
# 报错,提示找不到文件夹 /usr/local/include/freetype2/freetype/
# mkdir -p /usr/local/include/freetype2/freetype/ 然后再 make install
cd freetype-2.3.5
./configure
make
make install
# 报错,提示找不到文件夹 /usr/local/include/freetype2/freetype/internal
# 执行 mkdir -p /usr/local/include/freetype2/freetype/internal 然后再 make install
cd pierrejoye-gd-libgd-5551f61978e3/src
./configure --with-jpeg=/usr/local/jpeg8 --with-png -with-zlib -with-freetype=/usr/local/freetype
make
make install
cd pcre-8.31
./configure
make && make intall
groupadd nginx
useradd -g nginx nginx
cd nginx-1.3.4
./configure --user=nginx --group=nginx --with-http_stub_status_module --with-http_ssl_module --with-http_image_filter_module
# 本地如果要打开debug日志,需要添加--with-debug
make && make install